




Time passes but memories never fade… A minute to remember!
Exchange Online Introduces Office 365 Privileged Access Management
The content below is taken from the original ( Exchange Online Introduces Office 365 Privileged Access Management), to continue reading please visit the site. Remember to respect the Author & Copyright.

Controlling Elevated Access to Office 365
Traditionally, on-premises administrators are all-powerful and can access anything they want on the servers they manage. In the multi-tenant Office 365 cloud, Microsoft’s datacenter administrators are both few in number and constrained in terms of what they can do, and tenants must grant Microsoft access to their data if needed to resolve support incidents. Tenants with Office 365 E5 plans can use the Customer Lockbox feature to control support access to tenant data.
Privileged Access Management (PAM) for Office 365 is now generally available. PAM is based on the principle of Zero Standing Access, meaning that administrators do not have ongoing access to anything that needs elevated privileges. To perform certain tasks, administrators need to seek permission. When permission is granted, it is for a limited period and with just-enough access (JEA) to do the work. Figure 1 shows how the concept works.
 Figure 1: : Privileged Access Management (image credit: Microsoft)
Figure 1: : Privileged Access Management (image credit: Microsoft)This article examines the current implementation of PAM within Office 365. I don’t intend to repeat the steps outlined in the documentation for privileged access management or in a very good Practical365.com article here. Instead, I report my experiences of working with the new feature.
Only Exchange Online
Exchange is a large part of Office 365, but it’s only one workload. The first thing to understand about PAM is that it only covers Exchange Online. It’s unsurprising that the PAM developers focused on Exchange. Its implementation of role-based access control is broader, deeper, and more comprehensive than any other Office 365 workload. Other parts of Office 365, like SharePoint Online, ignore RBAC, while some like Teams are taking baby steps in implementing RBAC for service administration roles.
Privileged Access Configuration
PAM is available to any tenant with Office 365 E5 licenses. The first step is to create a mail-enabled security group (or reuse an existing group) who will serve as the default set of PAM approvers. Members of this group receive requests for elevated access generated by administrators. Like mailbox and distribution group moderation, any member of the PAM approver group can authorize a request.
To enable PAM for a tenant, go to the Settings section of the Office 365 Admin Center, open Security & Privacy, and go to the Privileged Access section. This section is split into two (Figure 2). Click the Edit button to control the tenant configuration, and the Manage access policies and requests link to define policies and manage the resulting requests for authorization.
 Figure 2: Privileged Access options in the Office 365 Admin Center (image credit: Tony Redmond)
Figure 2: Privileged Access options in the Office 365 Admin Center (image credit: Tony Redmond)To manage PAM, a user needs to be assigned at least the Role Management role, part of the Organization Management role group (in effect, an Exchange administrator). In addition, their account must be enabled for multi-factor authentication. If not, the Manage access policies and requests link shown in Figure 2 won’t be displayed.
By default, PAM is off and must be enabled by moving the slider for “require approval for privilege tasks” to On. You also select a PAM approver group at this point.
Configuration Settings
The settings are written into the Exchange Online configuration. We can see them by running the Get-OrganizationConfig cmdlet:
Get-OrganizationConfig | Selectn -Expand-Property ElevatedAccessControl Enabled:True; Mode:Default; AdminGroup:[email protected]; ApprovalPolicyCount:5; SystemAccounts:; NotificationMailbox:SystemMailbox{bb558c35-97f1-4cb9-8ff7-d53741dc928c}@office365itpros.onmicrosoft.com
Excepted Accounts
One interesting setting that the Office 365 Admin Center does not expose is the ability to define a set of accounts who are not subject to privileged access requests, such as accounts used to run PowerShell jobs in the background. To add some excepted accounts, run the Enable-ElevatedAccessControl cmdlet to rewrite the configuration (the only way to change a value). In this case, we specify a list of highly-privileged accounts (which should be limited in number) as system accounts. These accounts must, for now, be fully licensed and have Exchange Online mailboxes.
Enable-ElevatedAccessControl -AdminGroup '[email protected]' -SystemAccounts @('[email protected]', '[email protected]')
If you check the organization configuration for elevated access after running the command, you’ll see that the SystemAccounts section is now populated.
Access Policies
PAM policies allow tenants to set controls over individual tasks, roles, and role groups. If you are familiar with RBAC in Exchange Online, these terms are second nature to you. Briefly, a RBAC role defines one or more cmdlets and their parameters that someone holding the role can run, while a role group is composed of a set of roles. By supporting three types of policy, PAM allows tenants control at a very granular level for certain cmdlets while also having the ability to control higher-level roles.
As shown in Figure 3, the individual cmdlets chosen by PAM include adding a transport or journal rule, restoring a mailbox, adding an inbox rule, and changing permissions on mailboxes or public folders. Hackers or other malicious players might use to gain access to user mailboxes or messages. For instance, a hacker who penetrates a tenant might set up inbox rules to forward copies of messages to a mailbox on another system so that they can work out who does what within a company, information which is very helpful to them in constructing phishing or business email compromise attacks.
 Figure 3: Creating a new PAM Access Policy (image credit: Tony Redmond)
Figure 3: Creating a new PAM Access Policy (image credit: Tony Redmond)If you chose to create policies based on RBAC roles or role groups, the policies cover all the cmdlets defined in the chosen role or role group. You cannot add cmdlets, roles, or role groups to the set supported by PAM.
Each policy can have its own approval group. A policy can also be defined with an approval type of Manual, meaning that any request to use the commands within scope of the policy must receive explicit approval, or Auto, meaning that a request will be logged and automatically approved. Figure 4 shows a set of policies defined for a tenant.
 Figure 4: A set of PAM policies defined for a tenant (image credit: Tony Redmond)
Figure 4: A set of PAM policies defined for a tenant (image credit: Tony Redmond)Creating an Elevated Access Request
With PAM policies in place, users can request elevated access through the Office 365 Admin Center through the Access Requests section (Figure 4). A request specifies the type of access needed, the duration, and the reason why (Figure 5).
 Figure 5: Creating a new PAM request (image credit: Tony Redmond)
Figure 5: Creating a new PAM request (image credit: Tony Redmond)Although Exchange logs all PAM requests, it does not capture the information in the Office 365 audit log. This seems very strange as any request for elevated access is exactly the kind of event that should be recorded in the audit log.
Approving PAM Requests
When a PAM request is generated, Exchange Online creates an email notification generated from the mailbox pointed to in the organization configuration and sends it to the approval group (Figure 6). The person asking for approval is copied.
 Figure 6: Notification of pending access request (image credit: Tony Redmond)
Figure 6: Notification of pending access request (image credit: Tony Redmond)I found that the delay in receiving email notification about requests ranged from 3 minutes to over 40 minutes, so some education of administrators is needed to make them aware of how long it might take for the approvers to know about their request and then grant them access.
Approvers can also scan for incoming requests (or check the status of ongoing requests) in the Office 365 Admin Center. As you’d expect, self- approval is not allowed. Another administrator with the necessary rights must approve a request you make.
Upon approval, the requester receives notification of approval by email and can then go ahead and run the elevated command. An internal timer starts when the requester first runs the authorized command. They can continue to run the command as often as they need to during the authorized duration.
PAM by PowerShell
Cmdlets to control PAM are in the Exchange Online module. You must use MFA to connect to Exchange to run the cmdlets. You can run the cmdlets in a session created with basic authentication, but cmdlets fail unless they can authenticate with OAuth.
To start, here’s how to create a new request with the New-ElevatedAccessRequest cmdlet:
[uint32]$hours = 2 New-ElevatedAccessRequest -Task 'Exchange\Search-Mailbox' -Reason 'Need to search Kim Akers mailbox' -DurationHours $hours
Note the peculiarity that the cmdlet does not accept a simple number for the DurationHours parameter, which is why the duration is first defined in an unsigned 32-bit integer variable.
To see what requests are outstanding, run the Get-ElevatedAccessRequest command:
Get-ElevatedAccessRequest |? {$_.ApprovalStatus -eq "Pending"} | Format-Table DateCreatedUTC, RequestorUPN, RequestedAccess, Reason
DateCreatedUtc RequestorUPN RequestedAccess Reason
-------------- ------------ --------------- ------
5 Nov 2018 21:41:52 [email protected] Search-Mailbox Need to search Kim Akers mailbox
5 Nov 2018 18:20:03 [email protected] Search-Mailbox Need to look through a mailbox
The Approve-ElevatedAccessRequest cmdlet takes the identity of a request (as reported by Get-ElevatedAccessRequest) as its mandatory request identifier. For example:
Approve-ElevatedAccessRequest -RequestId 5e5adbdc-bfeb-4b01-a976-5ac9bf51aff0 -Comment "Approved due to search being necessary"
PowerShell signals an error promptly if you try to approve one of your own requests by running the Approve-ElevatedAccessRequest cmdlet, but the Office 365 Admin Center stays silent on the matter and doesn’t do anything.
Shortcomings and Problems for PAM
PAM for Office 365 is a promising idea that I strongly support. However, the current implementation is half-baked and incomplete. Here’s why I make that statement:
There’s a worrying lack of attention to detail in places like the prompt in the PAM configuration “require approval for privilege tasks” which should be privileged tasks. It’s a small but annoying grammatical snafu. Another instance is the way that the DurationHours parameter for New-ElevatedAccessRequest doesn’t accept simple numbers like every other PowerShell cmdlet in the Exchange Online module. Or the way that the Office 365 Admin Center proposes the first group found in the tenant as the default approval group when you go to update the PAM configuration, making it easy for an administrator to overwrite the default approval group with an utterly inappropriate choice. Seeing code like this released for general availability makes me wonder about the efficiency and effectiveness of Microsoft’s testing regime.
The lack of auditing is also worrying. Any use of privileged access or control over privileged access should be recorded in the Office 365 audit log. In some mitigation, audit records for the actual events (like running a mailbox search) are captured when they are executed.
The biggest issue is the tight integration with Exchange Online. Leveraging the way Exchange uses RBAC makes it easier for the developers to implement PAM, but only for Exchange Online. Other mechanisms will be needed to deal with SharePoint Online, OneDrive for Business, Teams, Planner, Yammer, and so on. Basing PAM on a workload-dependent mechanism is puzzling when so much of Office 365 now concentrates on workload-agnostic functionality.
Some organizations will find PAM useful today. Others will be disappointed because of the flaws mentioned above. We can only hope that Microsoft will address the obvious deficiencies in short order while working as quickly as possible to make “Privileged Access management in Office 365” (as announced) a reality.
The post Exchange Online Introduces Office 365 Privileged Access Management appeared first on Petri.
With Windows 1809 Delayed, OEMs are Shipping New Devices With Unsupported Software
The content below is taken from the original ( With Windows 1809 Delayed, OEMs are Shipping New Devices With Unsupported Software), to continue reading please visit the site. Remember to respect the Author & Copyright.


In late September, Microsoft signed off on the latest version of Windows 10, known as 1809. This version of Windows was released in October and after it was discovered that it was deleting user data, it was quickly pulled.
After it was pulled, the company uncovered another data deletion bug that was related to zip files. And while the company has released a new version of 1809 to insiders, for those who are not participating in this release, the company is not communicating anything about when it will be released; it could be tomorrow or it may not arrive until December.
For consumers, this isn’t all that big of a deal. Even for corporate customers, this does not impact anyone negatively other than for planning purposes, this could shift a few plans.
But for OEMs, this is a major headache and having talked to a couple of them off the record, they are not only stuck between a rock and a hard place, but they are also dealing with shipping hardware on untested software.
It’s no secret that the holiday shopping season is a crucial time for every retail company. Black Friday got its name from being a day when retailers would become profitable, or move into the black, for their annual sales and this year is fraught with challenges because of the delay of 1809.
For any OEM who built a laptop and was planning to ship it this fall with 1809, the challenges here are obvious. If they were using pre-release builds to validate their hardware knowing Windows would be updated to this release in the fall and then were forced to ship with 1803, there could be serious unforeseen issues with compatibility.
But this may not be the biggest issue with this release, companies who created marketing material for their devices that highlighted features from 1809 can’t start using that material until this version of Windows 10 ships. Considering that we are about 7 weeks from Christmas, the clock is ticking louder and louder each day that passes.
Heading into the holiday season, Microsoft began pitching ‘Always-connected PCs’, these devices used ARM-based CPUs, had LTE, and featured excellent battery-life. While the device category isn’t exactly new, there are new products running a SnapDragon 850 processors from Lenovo and Samsung which all parties involved hope would be big sellers this year.
But there is a major problem, Windows 10 1803 is not designed to run on a SnapDragon 850. So Microsoft had two options, ship a broken build of Windows 10 for these devices or let them run on an unsupported version of Windows 10; they chose to let them run on 1803.
I went to BestBuy today and found a Lenovo device with a Snapdragon 850 in it and it was running 1803. If you look at Microsoft’s official support documentation for versions of Windows and processors, the 850 is only designed to run on 1809 which is, right now, the Schrodinger’s version of Windows. Which means that the devices that are being sold right now, with a Snapdragon 850, are shipping with an untested iteration of Windows.

Lenovo YOGA C630 for sale at Best Buy
Worse, companies like Samsung and Lenovo are taking the biggest risk with these devices. They are backing a Microsoft initiative to move away from Intel and experiment with ARM and for their loyalty, Microsoft is not upholding its promise to ship a version of Windows on time.
Time and time again, I was told that Microsoft should ship 1809 when it is ready, and I do agree. The problem is that most people think about this from the consumer or end-user perspective, but from the OEM viewpoint, they are making serious bets about the availability of each version of Windows 10.
Microsoft’s decision to change how it tests software has proven to be a giant disaster. Yes, they are shipping versions of Windows faster, but on key releases for 2018, they missed both of their publicly stated deadlines. Even though Windows is less of a priority for Microsoft these days, the current development and shipping process is not sustainable and is starting to impact their most loyal partners.
The post With Windows 1809 Delayed, OEMs are Shipping New Devices With Unsupported Software appeared first on Petri.
Download Windows 10 Guides for Beginners from Microsoft
The content below is taken from the original ( Download Windows 10 Guides for Beginners from Microsoft), to continue reading please visit the site. Remember to respect the Author & Copyright.

While we at TheWindowsClub bring you some of the best guides on how you can use Windows in your daily life. If you are looking for a visual experience of different parts of Windows, Microsoft has got you covered. These […]
This post Download Windows 10 Guides for Beginners from Microsoft is from TheWindowsClub.com.
Cryptocurrency mogul wants to turn Nevada into the next center of Blockchain Technology
The content below is taken from the original ( Cryptocurrency mogul wants to turn Nevada into the next center of Blockchain Technology), to continue reading please visit the site. Remember to respect the Author & Copyright.


He imagines a sort of experimental community spread over about a hundred square miles, where houses, schools, commercial districts and production studios will be built. The centerpiece of this giant project will be the blockchain, a new kind of database that was introduced by Bitcoin.
Jeffrey Berns, who owns the cryptocurrency company Blockchains L.L.C., has bought 68,000 acres of land in Nevada that he hopes to transform into a community based around blockchain technology. His utopian vision, which would be the first ‘smart city‘ based on the technology, involves the creation of a new town along the Truckee river, with homes, apartments, schools, and a drone delivery system.
The first step will be constructing an 1,000 acre campus that will host startups and companies working on applications such as AI and 3D printing to help bring about the high-tech city. LA firms Tom Wiscombe Architecture and Ehrlich Yanai Rhee Chaney Architects have been hired to assist in this vision, designing the architecture and masterplan for the future city.


Photo Credit:and Tom Wiscombe Architecture.
Called Innovation Park, the designers contend the city will be ‘human-centric,’ while also planned around autonomous, electric vehicles. Housing types will range fro… type…
Cyber-crooks think small biz is easy prey. Here’s a simple checklist to avoid becoming an easy victim
The content below is taken from the original ( Cyber-crooks think small biz is easy prey. Here’s a simple checklist to avoid becoming an easy victim), to continue reading please visit the site. Remember to respect the Author & Copyright.
Make sure you’re spending your hard-earned cash on the ‘right’ IT security
Comment One of the unpleasant developments of the last decade has been the speed with which IT security threats, once aimed mainly at large enterprises, have spread to SMBs – small and medium businesses.…
Learn about AWS – November AWS Online Tech Talks
The content below is taken from the original ( Learn about AWS – November AWS Online Tech Talks), to continue reading please visit the site. Remember to respect the Author & Copyright.

AWS Online Tech Talks are live, online presentations that cover a broad range of topics at varying technical levels. Join us this month to learn about AWS services and solutions. We’ll have experts online to help answer any questions you may have.
Featured this month! Check out the tech talks: Virtual Hands-On Workshop: Amazon Elasticsearch Service – Analyze Your CloudTrail Logs, AWS re:Invent: Know Before You Go and AWS Office Hours: Amazon GuardDuty Tips and Tricks.
Register today!
Note – All sessions are free and in Pacific Time.
Tech talks this month:
AR/VR
November 13, 2018 | 11:00 AM – 12:00 PM PT – How to Create a Chatbot Using Amazon Sumerian and Sumerian Hosts – Learn how to quickly and easily create a chatbot using Amazon Sumerian & Sumerian Hosts.
Compute
November 19, 2018 | 11:00 AM – 12:00 PM PT – Using Amazon Lightsail to Create a Database – Learn how to set up a database on your Amazon Lightsail instance for your applications or stand-alone websites.
November 21, 2018 | 09:00 AM – 10:00 AM PT – Save up to 90% on CI/CD Workloads with Amazon EC2 Spot Instances – Learn how to automatically scale a fleet of Spot Instances with Jenkins and EC2 Spot Plug-In.
Containers
November 13, 2018 | 09:00 AM – 10:00 AM PT – Customer Showcase: How Portal Finance Scaled Their Containerized Application Seamlessly with AWS Fargate – Learn how to scale your containerized applications without managing servers and cluster, using AWS Fargate.
November 14, 2018 | 11:00 AM – 12:00 PM PT – Customer Showcase: How 99designs Used AWS Fargate and Datadog to Manage their Containerized Application – Learn how 99designs scales their containerized applications using AWS Fargate.
November 21, 2018 | 11:00 AM – 12:00 PM PT – Monitor the World: Meaningful Metrics for Containerized Apps and Clusters – Learn about metrics and tools you need to monitor your Kubernetes applications on AWS.
Data Lakes & Analytics
November 12, 2018 | 01:00 PM – 01:45 PM PT – Search Your DynamoDB Data with Amazon Elasticsearch Service – Learn the joint power of Amazon Elasticsearch Service and DynamoDB and how to set up your DynamoDB tables and streams to replicate your data to Amazon Elasticsearch Service.
November 13, 2018 | 01:00 PM – 01:45 PM PT – Virtual Hands-On Workshop: Amazon Elasticsearch Service – Analyze Your CloudTrail Logs – Get hands-on experience and learn how to ingest and analyze CloudTrail logs using Amazon Elasticsearch Service.
November 14, 2018 | 01:00 PM – 01:45 PM PT – Best Practices for Migrating Big Data Workloads to AWS – Learn how to migrate analytics, data processing (ETL), and data science workloads running on Apache Hadoop, Spark, and data warehouse appliances from on-premises deployments to AWS.
November 15, 2018 | 11:00 AM – 11:45 AM PT – Best Practices for Scaling Amazon Redshift – Learn about the most common scalability pain points with analytics platforms and see how Amazon Redshift can quickly scale to fulfill growing analytical needs and data volume.
Databases
November 12, 2018 | 11:00 AM – 11:45 AM PT – Modernize your SQL Server 2008/R2 Databases with AWS Database Services – As end of extended Support for SQL Server 2008/ R2 nears, learn how AWS’s portfolio of fully managed, cost effective databases, and easy-to-use migration tools can help.
DevOps
November 16, 2018 | 09:00 AM – 09:45 AM PT – Build and Orchestrate Serverless Applications on AWS with PowerShell – Learn how to build and orchestrate serverless applications on AWS with AWS Lambda and PowerShell.
End-User Computing
November 19, 2018 | 01:00 PM – 02:00 PM PT – Work Without Workstations with AppStream 2.0 – Learn how to work without workstations and accelerate your engineering workflows using AppStream 2.0.
Enterprise & Hybrid
November 19, 2018 | 09:00 AM – 10:00 AM PT – Enterprise DevOps: New Patterns of Efficiency – Learn how to implement “Enterprise DevOps” in your organization through building a culture of inclusion, common sense, and continuous improvement.
November 20, 2018 | 11:00 AM – 11:45 AM PT – Are Your Workloads Well-Architected? – Learn how to measure and improve your workloads with AWS Well-Architected best practices.
IoT
November 16, 2018 | 01:00 PM – 02:00 PM PT – Pushing Intelligence to the Edge in Industrial Applications – Learn how GE uses AWS IoT for industrial use cases, including 3D printing and aviation.
Machine Learning
November 12, 2018 | 09:00 AM – 09:45 AM PT – Automate for Efficiency with Amazon Transcribe and Amazon Translate – Learn how you can increase efficiency and reach of your operations with Amazon Translate and Amazon Transcribe.
Mobile
November 20, 2018 | 01:00 PM – 02:00 PM PT – GraphQL Deep Dive – Designing Schemas and Automating Deployment – Get an overview of the basics of how GraphQL works and dive into different schema designs, best practices, and considerations for providing data to your applications in production.
re:Invent
November 9, 2018 | 08:00 AM – 08:30 AM PT – Episode 7: Getting Around the re:Invent Campus – Learn how to efficiently get around the re:Invent campus using our new mobile app technology. Make sure you arrive on time and never miss a session.
November 14, 2018 | 08:00 AM – 08:30 AM PT – Episode 8: Know Before You Go – Learn about all final details you need to know before you arrive in Las Vegas for AWS re:Invent!
Security, Identity & Compliance
November 16, 2018 | 11:00 AM – 12:00 PM PT – AWS Office Hours: Amazon GuardDuty Tips and Tricks – Join us for office hours and get the latest tips and tricks for Amazon GuardDuty from AWS Security experts.
Serverless
November 14, 2018 | 09:00 AM – 10:00 AM PT – Serverless Workflows for the Enterprise – Learn how to seamlessly build and deploy serverless applications across multiple teams in large organizations.
Storage
November 15, 2018 | 01:00 PM – 01:45 PM PT – Move From Tape Backups to AWS in 30 Minutes – Learn how to switch to cloud backups easily with AWS Storage Gateway.
November 20, 2018 | 09:00 AM – 10:00 AM PT – Deep Dive on Amazon S3 Security and Management – Amazon S3 provides some of the most enhanced data security features available in the cloud today, including access controls, encryption, security monitoring, remediation, and security standards and compliance certifications.



The Gemini PDA’s follow-up is a clamshell communicator phone
The content below is taken from the original ( The Gemini PDA’s follow-up is a clamshell communicator phone), to continue reading please visit the site. Remember to respect the Author & Copyright.

MusicBrainz introducing: Genres!
The content below is taken from the original ( MusicBrainz introducing: Genres!), to continue reading please visit the site. Remember to respect the Author & Copyright.
One of the things various people have asked MusicBrainz for time and time again has been genres. However, genres are hard to do right and they’re very much subjective—with MusicBrainz dealing almost exclusively with objective data. It’s been a recurring discussion on almost all of our summits, but a couple years ago (with some help from our friend Alastair Porter and his research colleagues at UPF), we finally came to a path forward—and recently Nicolás Tamargo (reosarevok) finally turned that path forward into code… which has now been released! You can see it in action on e.g., Nine Inch Nails’ Year Zero release group.
How does it work?
For now genres are exactly the same as (folksonomy) tags behind the scenes; some tags simply have become the chosen ones and are listed and presented as genres. The list of which tags are considered as genres is currently hardcoded, and no doubt it is missing a lot of our users’ favourite genres. We plan to expand the genre list based on your requests, so if you find a genre that is missing from it, request it by adding a style ticket with the “Genres” component.
As we mentioned above, genres are very subjective, so just like with folksonomy tags, you can upvote and downvote genres you agree or disagree with on any given entity, and you can also submit genre(s) for the entity that no one has added yet.
What about the API?
A bunch of the people asking for genres in MusicBrainz have been application developers, and this type of people are usually more interested in how to actually extract the genres from our data.
The method to request genres mirrors that of tags: you can use inc=genres to get all the genres everyone has proposed for the entity, or inc=user-genres to get all the genres you have proposed yourself (or both!). For the same release group as before, you’d want https://musicbrainz.org/ws/2/release-group/3bd76d40-7f0e-36b7-9348-91a33afee20e?inc=genres+user-genres for the XML API and https://musicbrainz.org/ws/2/release-group/3bd76d40-7f0e-36b7-9348-91a33afee20e?inc=genres+user-genres&fmt=json for the JSON API.
Since genres are tags, all the genres will continue to be served with inc=tags as before as well. As such, you can always use the tag endpoint if you would rather filter the tags by your own genre list rather than follow the MusicBrainz one, or if you want to also get other non-genre tags (maybe you want moods, or maybe you’re really interested in finding artists who perform hip hop music and were murdered – we won’t stop you!).
I use the database directly, not the API
You can parse the tag→genres from entities.json in the root of the “musicbrainz-server” repository which will give you a list of what we currently consider genres. Then you can simply compare any folksonomy tags from the %_tag tables.
Note about licensing
One thing to keep in mind for any data consumers out there is that, as per our data licensing, tags—and thus also genres—are not part of our “core (CC0-licensed) data”, but rather part of our “supplementary data” which is available under a Creative Commons Attribution-ShareAlike-NonCommercial license. Thus, if you wish to use our genre data for something commercial, you should get a commercial use license from the MetaBrainz Foundation. (Of course, if you’re going to provide a commercial product using data from MusicBrainz, you should always sign up as a supporter regardless. :)).
The future?
We are hoping to get a better coverage of genres (especially genres outside of the Western tradition, of which we have a very small amount right now) with your help! That applies both to expanding the genre list and actually applying genres to entities. For the latter, remember that everyone can downvote your genre suggestion if they don’t agree, so don’t think too much about “what genres does the world think apply to this artist/release/whatever”. Just add what you feel is right; if everyone does that we’ll get much better information. 
In the near future we’re hoping to move the genre list from the code to the database (which shouldn’t mean too much for most of you, other than less waiting between a new genre being proposed for the list and it being added, but is much better for future development). Also planned is a way to indicate that several tags are the same genre (so that if you tag something as “hiphop”, “hip hop” or “hip-hop” the system will understand that’s really all the same). Further down the line, who knows! We might eventually make genres into limited entities of a sort, in order to allow linking to, say, the appropriate Wikidata/Wikipedia pages. We might do some fun stuff. Time will tell!

Serverless from the ground up: Connecting Cloud Functions with a database (Part 3)
The content below is taken from the original ( Serverless from the ground up: Connecting Cloud Functions with a database (Part 3)), to continue reading please visit the site. Remember to respect the Author & Copyright.
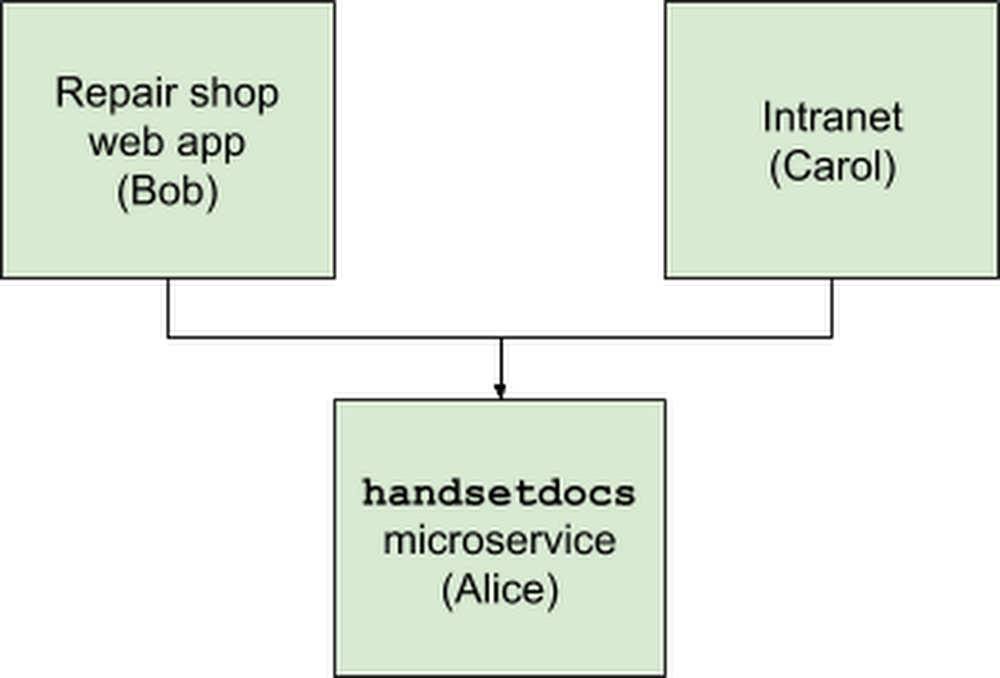
A few months have passed since Alice first set up a central document repository for her employer Blueprint Mobile, first with a simple microservice and Google Cloud Functions (part 1), and then with Google Sheets (part 2). The microservice is so simple to use and deploy that other teams have started using it too: the procurement team finds the system very handy for linking each handset to the right invoices and bills, while the warehouse team uses the system to look up orders. However, these teams work with so many documents that the system is sometimes slow. And now Alice’s boss wants her to fix it to support these new use cases.
Alice, Bob, and Carol are given a few days to brainstorm how to improve their simple team hack and turn it into a sustainable corporate resource. So they decide to store the data in a database, for better scaling, as well as to be able to customize it for new use cases in the future.
Alice consults the decision flow-chart for picking a Google Cloud storage product. Her data is structured, won’t be used for analytics, and isn’t relational. She has a choice of Cloud Firestore or Cloud Datastore. Both would work fine, but after reading about the differences between them, she decides to use Cloud Firestore, a flexible, NoSQL database popular for developing web and mobile apps. She likes that Cloud Firestore is a fully managed product—meaning that she won’t have to worry about sharding, replication, backups, database instances, and so on. It also fits well with the serverless nature of the Cloud Functions that the rest of her system uses. Finally, her company will only pay for how much they use, and there is no minimum cost—her app’s database use might even fit within the free quota!
First she needs to enable Firestore in the GCP Console. Then, she follows the docs page recommendation for new server projects and installs the Node client library for the Cloud Datastore API, with which Firestore is compatible:
Now she is ready to update her microservice code. The functions handsetdocs() and handleCors() remain the same. The function getHandsetDocs() is where all the action is. For optimal performance, she makes Datastore a global variable for reuse in future invocations. On the query line, she asks for all entities of type Doc, ordered by the handset field. At the end of the function she returns the zeroth element of the result, which holds the entities.
When she has deployed the function, Alice runs into Bob again. Bob is excited about putting the data in a safer place, but wonders how his team will enter new docs in the system. The technicians, and everyone else at the company, have grown used to using the Sheet.
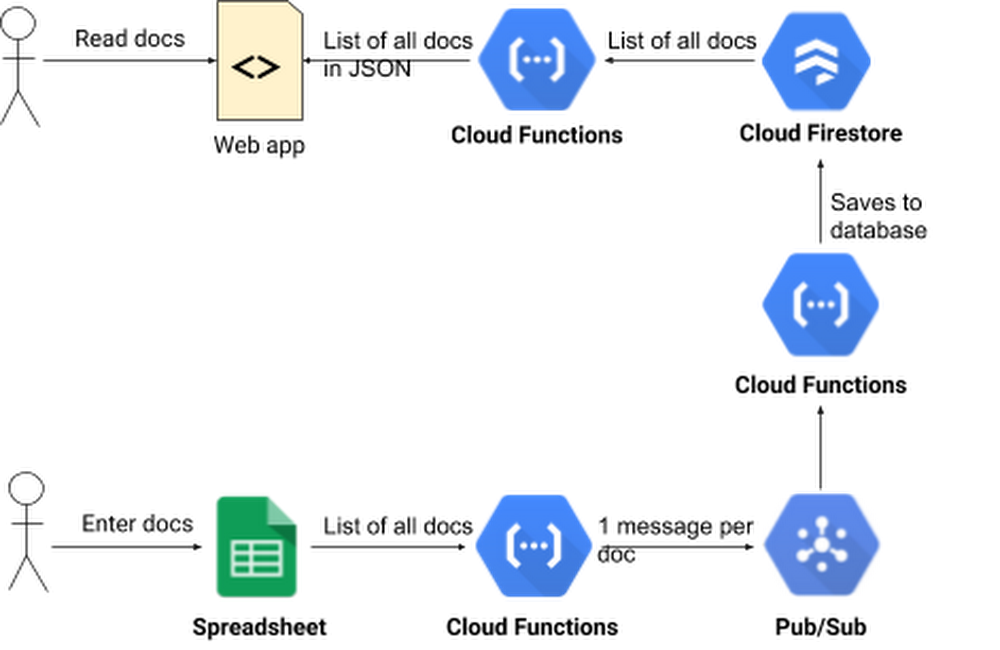
One way solution is to write a function that reads all the rows in the spreadsheet, loops over them and saves each one to the datastore. But what if there’s a failure before all the database operations have executed? Some records will be in the datastore, while others won’t. Alice does not want to build complex logic for detecting such a failure, figuring out which records weren’t copied, and retrying those.
Then she reads about Cloud Pub/Sub, a service for ingesting real-time event streams, and an important tool when building event-driven computing systems. She realizes she can write code to read all the docs from the spreadsheet, and then publish one Pub/Sub message per doc. Then, another microservice (also built in Cloud Functions) is triggered by the Pub/Sub messages that reads the doc found in the Pub/Sub message and writes it to the datastore.
First Alice goes to Pub/Sub in the console and creates a new topic called IMPORT. Then she writes the function that publishes one Pub/Sub message per spreadsheet record. It calls getHandsetDocsFromSheet() to get all the docs from the spreadsheet. This function is really just a renamed version of the getHandsetDocs() function from part 2 of this series. Then the function calls publishPubSubMessages() which publishes one Pub/Sub message per doc.
The publishPubSubMessages() function loops over the docs and publishes one Pub/Sub message for each one. It returns when all messages have been published.
Alice then writes the function that is triggered by these Pub/Sub messages. The function doesn’t need any looping because it is invoked once for every Pub/Sub message, and every message contains exactly one doc.
The function starts by extracting the JSON structure from the Pub/Sub message. Then it creates a Datastore instance if one isn’t available from the last time it ran. Datastore save operations need a key object and a data object. Alice’s code makes doc.id the key. Then she deletes the id property from doc. That way another id column will not be created when she calls save(). If there’s a record with the given id, it is updated. If there isn’t, a new record is created. Then the function returns the result of the save() call, so that the result of the operation (success or failure) gets captured in the log, along with any error messages.
Finally, there needs to be a way to start the data export from the spreadsheet to the database. That is done by hitting the URL for the startImport() function above. In theory, Alice or Bob could do that by pasting that URL into their browser, but that’s awkward. It would be better if any employee could trigger the data export when they are done editing the spreadsheet.
Alice opens the spreadsheet, selects the Tools menu and clicks Script Editor. By entering the Apps Script code below she creates a new menu named “Data Import” in the spreadsheet. It has a single menu item, “Import data now”. When the user selects that menu item, the script hits the URL of the startImport() function, which starts the process for importing the spreadsheet into the database.

Alice takes a moment to consider the system she has built:
-
An easy-to-use data entry front-end using Sheets.
-
A robust way to get spreadsheet data into a database, which scales well and has a good response time.
-
A microservice that serves the whole company as a source of truth for documents.
And it all took less than 100 lines of Cloud Functions code to do it! Alice proudly calls this version 1.0 of the microservice, and calls it a day. Meanwhile, Alice’s co-workers are grateful for her initiative, and impressed by how well she represented her team.
You too, can be a hero in your organization, by solving complex business integration problems with the help of intuitive, easy-to-use serverless computing tools. We hope this series has whetted your appetite for all the cool things you can do with some basic programming skills and tools like Cloud Functions, Cloud Pub/Sub and Apps Script. Follow the Google Cloud Functions Quickstart and you’ll have your first function deployed in minutes.
Paper Airplane Database has the Wright Stuff
The content below is taken from the original ( Paper Airplane Database has the Wright Stuff), to continue reading please visit the site. Remember to respect the Author & Copyright.
We’ve always had a fascination with things that fly. Sure, drones are the latest incarnation of that, but there have been RC planes, kites, and all sorts of flying toys and gizmos even before manned flight was possible. Maybe the first model flying machine you had was a paper airplane. There’s some debate, but it appears the Chinese and Japanese made paper airplanes 2,000 years ago. Now there’s a database of paper airplane designs, some familiar and some very cool-looking ones we just might have to try.
If you folded the usual planes in school, you’ll find those here. But you’ll also find exotic designs like the Sea Glider and the UFO. The database lets you select from planes that work better for distance, flight time, acrobatics, or decoration. You can also select the construction difficulty and if you need to make cuts in the paper or not. There are 40 designs in all at the moment. There are step-by-step instructions, printable folding instructions, and even YouTube videos showing how to build the planes.
In addition to ancient hackers in China and Japan, Leonardo Da Vinci was known to experiment with paper flying models, as did aviation pioneers like Charles Langley and Alberto Santos-Dumont. Even the Wright brothers used paper models in the wind tunnel. Jack Northrop and German warplane designers have all used paper to validate their designs, too.
Modern paper planes work better than the ones from our youth. The current world record is 27.9 seconds aloft and over 226 feet downrange (but not the same plane; those are two separate records). In 2011, 200 paper planes carrying data recorders were dropped from under a weather balloon at a height of 23 miles. Some traveled from their starting point over Germany to as far away as North American and Australia.
If the 40 designs in the database just make you want more, there’s a large set of links on Curlie. And there’s [Alex’s] site which is similar and has some unique designs. We’d love to see someone strap an engine on some of these. If you are too lazy to do your own folding, there’s this. If you want to send out lots of planes, you can always load them into a machine gun.


Serverless from the ground up: Adding a user interface with Google Sheets (Part 2)
The content below is taken from the original ( Serverless from the ground up: Adding a user interface with Google Sheets (Part 2)), to continue reading please visit the site. Remember to respect the Author & Copyright.
Welcome back to our “Serverless from the ground up” series. Last week, you’ll recall, we watched as Alice and Bob built a simple microservice using Google Cloud Functions to power a custom content management system for their employer Blueprint Mobile. Today, Bob drops by Alice’s desk to share some good news. Blueprint Mobile will start selling and repairing handsets from the popular brand Foobar Cellular. Not only is Foobar Cellular wildly popular with customers, but it’s also really good at documenting its products. Each handset comes with scores of documents. And it releases new handsets all the time.
Alice realizes that it’s time for her simple v0.1 solution to scale up. Adding a new doc to the getHandsetDocs() function every few days isn’t so bad, but adding hundreds of documents would make for a tedious afternoon. Besides, this service has become a core resource for the team, and Alice has been wanting to improve it, but just hasn’t found the time. Supporting Foobar Cellular products is the motivating factor she needs, so she clears her schedule for the rest of the day and gets to work.
This time, Alice wants any technician to be able to add docs to the system, regardless of their ability to write or deploy code. No team resource should ever depend on a single employee, after all. So she’ll need to create a friendly user interface from which other employees can view, add, update, and delete the docs. Alice considers writing a web app to enable this, but that would take days and she can’t ignore her other responsibilities for that long.
Since everyone at the company already has access to G Suite, Alice decides to use Google Sheets as the user interface for viewing, adding, updating and deleting docs. This has the advantage of being collaborative, and makes it easy to manage editing rights. Most importantly, Alice knows she can put this together in a single day.
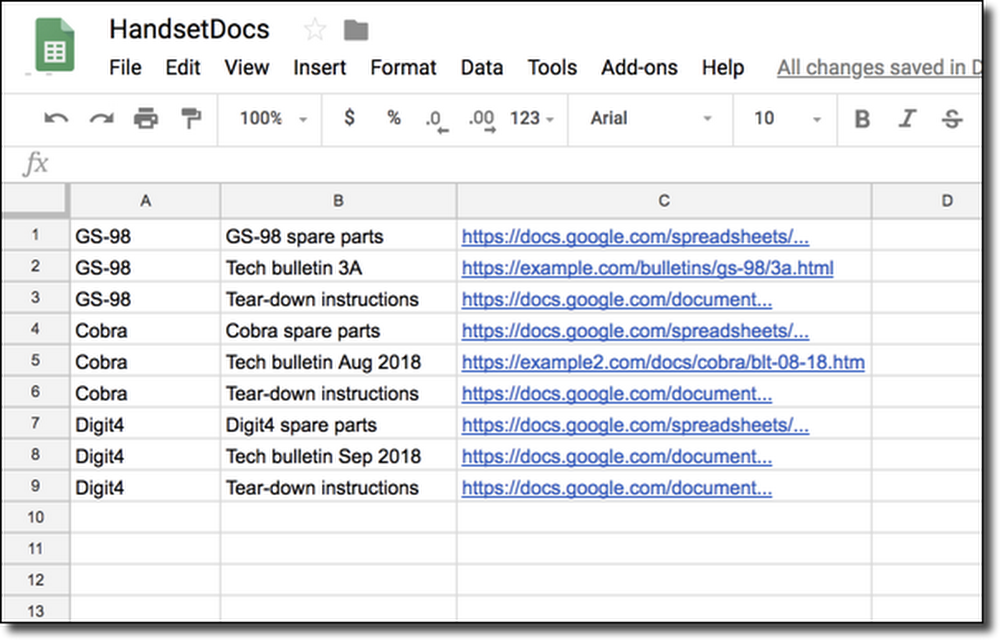
First, Alice creates a spreadsheet and adds a few document records for testing:
In order for the Google Sheet to communicate with her existing cloud functions, Alice looks up the email address of the auto-generated service account in the Google Cloud Console for the project. She clicks the Share button in the spreadsheet and gives that email address “read-only” access to the spreadsheet.
Now she is ready to update her microservice code. She reads up on the Google Sheets API and learns that the calls to read from a spreadsheet are asynchronous. That means she needs to tweak the entry function to make it accept an asynchronous response from getHandsetDocs():
Then she writes a new version of the getHandsetDocs() function. The previous version of that function contained a hard-coded list of all docs. The new version will read them from the spreadsheet instead.
First she needs to install the googleapis library in her local Node environment:
Then she gets the spreadsheet ID from its URL:
Now Alice has everything she needs to code the function that reads from the spreadsheet. The first few lines of the function create an auth object for the spreadsheets scope. No tokens or account details are needed because Cloud Functions support Application Default Credentials. This means the code below will run with the access rights of the default service account in the project.
After getting the auth object, the code creates a handle to the Sheets API and calls values.get() to read from the sheet. The call takes the sheet’s ID and the region of the sheet to read as parameters. The result is a two-dimensional array of cell values. Alice’s code repackages this as a one-dimensional array of objects with the properties handset, name and url. Those are the properties that the clients to the handset microservice expect.
Now any technician can maintain the list of documents simply by updating a Google Sheet. Alice’s handsetdocs microservice returns data with the same structure as before, so Bob’s web app does not need to be updated. And best of all, Alice won’t have to drop what she is doing every time there’s a new doc to add to the repository! Alice proudly calls this version 0.2 of the app and sends an email to the team sharing the new Google Sheet.
Using Google Sheets as the user interface into Alice’s microservice is a big success, and departments across the company are clamoring to use the system. Stay tuned next week, when Alice, Bob and Carol make the system more scalable by replacing the Sheets backend with a database.
What’s new in PowerShell in Azure Cloud Shell
The content below is taken from the original ( What’s new in PowerShell in Azure Cloud Shell), to continue reading please visit the site. Remember to respect the Author & Copyright.
At Microsoft Ignite 2018, PowerShell in Azure Cloud Shell became generally available. Azure Cloud Shell provides an interactive, browser-accessible, authenticated shell for managing Azure resources from virtually anywhere. With multiple access points, including the Azure portal, the stand-alone experience, Azure documentation, the Azure mobile app, and the Azure Account Extension for Visual Studio Code, you can easily gain access to PowerShell in Cloud Shell to manage and deploy Azure resources.
Improvements
Since the public preview in September 2017, we’ve incorporated feedback from the community including faster start-up time, PowerShell Core, consistent tooling with Bash, persistent tool settings, and more.
Faster start-up
At the beginning of PowerShell in Cloud Shell’s public preview, the experience opened in about 120 seconds. Now, with many performance updates, the PowerShell experience is available in about the same amount of time as a Bash experience.
PowerShell Core
PowerShell is now cross-platform, open-source, and built for heterogeneous environments and the hybrid cloud. With the Azure PowerShell and Azure Active Directory (AAD) modules for PowerShell Core, both now in preview, you are still able to manage your Azure resources in a consistent manner. By moving to PowerShell Core, the PowerShell experience in Cloud Shell can now run on a Linux container.
Consistent tooling
With PowerShell running on Linux, you get a consistent toolset experience across the Bash and PowerShell experiences. Additionally, all contents of the home directory are persisted, not just the contents of the clouddrive. This means that settings for tools, such as GIT and SSH, are persisted across sessions and are available the next time you use Cloud Shell.
Azure VM Remoting cmdlets
You have access to 4 new cmdlets, which include Enable-AzVMPSRemoting, Disable-AzVMPSRemoting, Invoke-AzVMCommand, and Enter-AzVM. These cmdlets enable you to easily enable PowerShell Remoting on both Linux and Windows virtual machines using ssh and wsman protocols respectively. This allows you to connect interactively to individual machines, or one-to-many for automated tasks with PowerShell Remoting.
Watch the “PowerShell in Azure Cloud Shell general availability” Azure Friday video to see demos of these features, as well as an introduction to future functionality!
Get started
Azure Cloud Shell is available through the Azure portal, the stand-alone experience, Azure documentation, the Azure Mobile App, and the Azure Account Extension for Visual Studio Code. Our community of users will always be the core of what drives Azure and Cloud Shell.
We would like to thank you, our end-users and partners, who provide invaluable feedback to help us shape Cloud Shell and create a great experience. We look forward to receiving more through the Azure Cloud Shell UserVoice.
News nybble: CJE/4D at London Show – place your orders now
The content below is taken from the original ( News nybble: CJE/4D at London Show – place your orders now), to continue reading please visit the site. Remember to respect the Author & Copyright.
CJE Micro’s and 4D will once again be exhibiting at the London Show and expect to have plenty of goodies on display, such as small HDMI monitors, the pi-topRO 2 Pi-based laptop, the 4D/Simon Inns Econet Clock, and a new IDE Podule (details of which to be announced RSN), and much more. However, the company […]
News nybble: CJE/4D at London Show – place your orders now
The content below is taken from the original ( News nybble: CJE/4D at London Show – place your orders now), to continue reading please visit the site. Remember to respect the Author & Copyright.
CJE Micro’s and 4D will once again be exhibiting at the London Show and expect to have plenty of goodies on display, such as small HDMI monitors, the pi-topRO 2 Pi-based laptop, the 4D/Simon Inns Econet Clock, and a new IDE Podule (details of which to be announced RSN), and much more. However, the company […]
Wi-Fi site survey tips
The content below is taken from the original ( Wi-Fi site survey tips), to continue reading please visit the site. Remember to respect the Author & Copyright.
Wi-Fi can be fickle. The RF signals and wireless devices don’t always do what’s expected – it’s as if they have their own minds at times. A Wi-Fi network that’s been quickly or inadequately designed can be even worse, spawning endless complaints from Wi-Fi users. But with proper planning and surveying, you can better design a wireless network, making you and your Wi-Fi users much happier. Here are some tips for getting started with a well-planned Wi-Fi site survey.
Use the right tools for the job
If you’re only trying to cover a small building or area that requires a few wireless access points (AP), you may be able to get away with doing a Wi-Fi survey using a simple Wi-Fi stumbler or analyzer on your laptop or mobile device. You’ll even find some free apps out there. Commercial options range from a few dollars to thousands of dollars for the popular enterprise vendors.
To read this article in full, please click here
(Insider Story)
Wi-Fi site-survey tips: How to avoid interference, dead spots
The content below is taken from the original ( Wi-Fi site-survey tips: How to avoid interference, dead spots), to continue reading please visit the site. Remember to respect the Author & Copyright.
Wi-Fi can be fickle. The RF signals and wireless devices don’t always do what’s expected – it’s as if they have their own minds at times.
To read this article in full, please click here
(Insider Story)
Managing Office 365 Guest Accounts
The content below is taken from the original ( Managing Office 365 Guest Accounts), to continue reading please visit the site. Remember to respect the Author & Copyright.


The Sharing Side of Office 365
Given the array of Office 365 apps that now support external sharing – Teams, Office 365 Groups, SharePoint Online, Planner, and OneDrive for Business – it should come as no surprise that guest user accounts accumulate in your tenant directory. And they do – in quantity, especially if you use Teams and Groups extensively.
The Guest Lifecycle
Nice as it is to be able to share with all and sundry, guest accounts can pose an administrative challenge. Creating guest accounts is easy, but a lack of out-of-the-box tools exist to manage the lifecycle of those accounts. Left alone, the accounts are probably harmless unless a hacker gains control over the account in the home domain associated with a guest account. But it is a good idea to review guest accounts periodically to understand what guests are present in the tenant and why.
Guest Toolbox
You can manage guest accounts using through the Users blade of the Azure portal (Figure 1), which is where you can add a photo for a guest account (with a JPEG file of less than 100 KB) or change the display name for a guest to include their company name. You can also edit some settings for guest accounts with the Office 365 Admin Center.

Figure 1: Guest accounts in the Azure portal (image credit: Tony Redmond)
Of course, there’s always PowerShell. Apart from working with accounts, you can use PowerShell to set up a policy to block certain domains so that your tenant won’t allow guests from those domains. That’s about the extent of the toolkit.
Guest and External Users
Before we look any further, let’s make it clear that the terms “guest user” and “external user” are interchangeable. In the past, Microsoft used external user to describe someone from outside your organization. Now, the term has evolved to “guest user” or “guest,” which is what you’ll see in Microsoft’s newest documentation (for Groups and Teams).
Guest Accounts No Longer Needed for SharePoint Sharing
Another thing that changed recently is the way Microsoft uses guest user accounts for sharing. Late last year, Microsoft introduced a new sharing model for SharePoint Online and OneDrive for Business based on using security codes to validate recipients of sharing invitations. Security codes are one-time eight-digit numbers sent to an email address contained in a sharing invitation to allow them to open content. Codes are good for 15 minutes.
Using security codes removed the need to create guests in the tenant directory. But if guests come from another Office 365 tenant, it makes sense for them to have a guest account and be able to have the full guest experience. Microsoft updated the sharing mechanism in June so that users from other Office 365 tenants go through the one-time code verification process. If successful, Office 365 creates a guest account for them and they can then sign in with their Office 365 credentials.
You can still restrict external sharing on a tenant-wide or site-specific basis so that users can share files only with guest accounts. In this case, guest credentials are used to access content. To find out just what documents guests access in your SharePoint sites, use the techniques explained in this article.
Guests can Leave
With Office 365 creating guest accounts for so many applications, people can end up with accounts in tenants that they don’t want to belong to. Fortunately, you can leave a tenant and have your account removed from that tenant’s directory.
Teams and Groups
Tenants that have used Office 365 for a while are likely to have some guest accounts in their directory that SharePoint or OneDrive for Business created for sharing. But most guest accounts created are for Office 365 Groups or Teams, which is the case for the guests shown in Figure 1.
Guest Accounts
We can distinguish guest accounts from normal tenant accounts in several ways. First, guests have a User Principal Name constructed from the email address in the form:
username_domain#EXT#@tenantname.onmicrosoft.com
For instance:
Jon_outlook.com#EXT#@office365itpros.onmicrosoft.com
Second, the account type is “Guest,” which means that we can filter guests from other accounts with PowerShell as follows:
Get-AzureADUser -Filter "UserType eq 'Guest'" -All $true|'Guest'|Format-Table Displayname, Mail
Note the syntax for the filter, which follows the ODATA standard.
Accounts created for guests that are incomplete because the guest has not gone through the redemption process have blank email addresses. Now that we know what guest accounts look like, we can start to control their lifecycle through PowerShell.
Checking for Unwanted Guests
Creating a deny list in the Azure AD B2B collaboration policy is a good way to stop group and team owners adding guests from domains that you don’t want, like those belonging to competitors. However, because Office 365 Groups have supported guest access since August 2016, it might be that some wanted guests are present. We can check guest membership with code like this:
$Groups = (Get-UnifiedGroup -Filter {GroupExternalMemberCount -gt 0} -ResultSize Unlimited | Select Alias, DisplayName)
ForEach ($G in $Groups)
{ $Ext = Get-UnifiedGroupLinks -Identity $G.Alias -LinkType Members
ForEach ($E in $Ext) {
If ($E.Name -Match "#EXT#")
{ Write-Host "Group " $G.DisplayName "includes guest user" $E.Name }
}
}
Because Office 365 Groups and Teams share common memberships, the code reports guests added through both Groups and Teams.
Removing Unwanted Guests
If we find guests belonging to an unwanted domain, we can clean them up by removing their accounts. This code removes all guest accounts belonging to the domain “Unwanted.com,” meaning that these guests immediately lose their membership of any team or group they belong to as well as access to any files shared with them. Don’t run destructive code like this unless you are sure that you want to remove these accounts.
$Users = (Get-AzureADUser -Filter "UserType eq 'Guest'" -All $True| Select DisplayName, ObjectId)
ForEach ($U in $Users)
{ If ($U.UserPrincipalName -Like "*Unwanted.com*") {
Write-Host "Removing"$U.DisplayName
Remove-AzureADUser -ObjectId $U.ObjectId }
}
Lots to Do
People are excited that Teams now supported guest access for any email address. However, as obvious in this discussion, allowing external users into your tenant is only the start of a lifecycle process that needs to be managed. It is surprising how many have never thought through how they will manage these accounts, but now that external access is more widespread, perhaps that work will begin.
Follow Tony on Twitter @12Knocksinna.
Want to know more about how to manage Office 365? Find what you need to know in “Office 365 for IT Pros”, the most comprehensive eBook covering all aspects of Office 365. Available in PDF and EPUB formats (suitable for iBooks) or for Amazon Kindle.
The post Managing Office 365 Guest Accounts appeared first on Petri.
Managing Windows 10 Updates in a Small Businesses Environment
The content below is taken from the original ( Managing Windows 10 Updates in a Small Businesses Environment), to continue reading please visit the site. Remember to respect the Author & Copyright.


In this article, I’ll look at some of the ways you can manage Windows Update to give you a more reliable computing experience.
This year has been a disaster for Windows Update and Microsoft’s Windows-as-a-Service delivery model. Both the Spring and Fall Windows 10 feature updates proved to be problematic. So much so that Microsoft was forced to pull the October 2018 Update from its servers. And shortly after October’s Patch Tuesday, Microsoft rolled out a buggy Intel HD Audio driver to some Windows 10 users that caused sound to stop working.
Despite these issues and the bad publicity, Windows Update is unlikely to get more reliable any time soon. Because for most of Microsoft’s enterprise customers, the problems consumers and small businesses face are usually not a concern as they have managed environments and the resources to test updates and implement phased deployments.
But whether you are a one-man band or a small business, there are some basic things you can do to ensure that Windows Update doesn’t ruin your day.
Windows 10 Home Isn’t for You
Windows 10 Home isn’t suitable for any kind of business environment. That should be perfectly obvious but still I come across people that insist on using Home edition for their business needs. And while there are key business features missing from Home, like the ability to join an Active Directory domain, the biggest reason not to use Home is that you have no control over Windows Update. Microsoft will force a Windows 10 feature update on you every 6 months regardless of whether it is stable or widely tested. That’s because as a Windows 10 Home user, you are going to test feature updates for Microsoft before they are deemed ‘ready’ for more valuable enterprise customers.
Windows Update for Business
Small businesses that don’t have the resources to deploy Windows Server Update Services (WSUS) can instead use Windows Update for Business (WUfB). WUfB lets you test updates in deployment ‘rings’ so that some users receive updates for validation before they are rolled out more widely. Or you can simply defer updates to be more confident that any serious issues have already been resolved by Microsoft as the update was distributed publicly.
WUfB doesn’t require any infrastructure to be installed and it relies on the peer-to-peer technology in Windows 10 to efficiently distribute updates to devices on the local area network, so a server isn’t needed. But it doesn’t have the reporting facilities provided by WSUS. WUfB is configured using Group Policy, Mobile Device Management (MDM), or in the Settings app.
If you don’t have the infrastructure in place to manage WUfB using Group Policy or MDM, I recommend changing the feature update branch from Semi-Annual Channel (Targeted), which is the default setting, to Semi-Annual Channel in the Settings app on each device manually. This will stop them receiving feature updates until a few months after general availability, when Microsoft deems the update suitable for widespread use in organizations. Devices will continue to receive quality updates, which include security patches, during this period.

Windows Update for Business in the Windows 10 Settings app (Image Credit: Russell Smith)
For more information on how to use Windows Update for Business, see Understanding Windows Update for Business and What Has Changed in Windows Update for Business on Petri.
Windows 10 Feature Update Support Lifecycle
Starting with Windows 10 version 1809, Microsoft will support all Enterprise and Education edition Fall feature updates for 30 months. The Spring feature updates will be supported for 18 months. Users running Home and Pro will get 18 months’ support for both Spring and Fall releases.
Do Not Include Drivers with Windows Updates
Hardware manufacturers can also use Windows Update to distribute device drivers. But quite often, drivers break devices or cause other issues. The latest example of this was the Intel HD Audio driver distributed to some Windows 10 devices at the end of last week that stopped sound from working. Microsoft took several days to issue another update to reverse the change and uninstall the buggy driver.
Forced driver updates via Windows Updates tend to cause more issues for legacy hardware. But nevertheless, last week’s Windows Update debacle affected new hardware too. Fortunately, it is possible to stop Windows 10 delivering device drivers through Windows Update. For more information on how to block automatic driver updates, see How To Stop Windows 10 Updating Device Drivers on Petri.
Windows Analytics Update Compliance
Windows Update isn’t as robust as it could be and sometimes fails due to network issues, database corruption, and failed updates so you can’t assume that your devices are compliant. Windows Analytics is a cloud service from Microsoft that provides information on the update status of Windows 10 devices. It uses Azure Log Analytics (previously Operations Management Suite) and it is free for Windows 10 Professional, Enterprise, and Education SKUs.
Before you can use Update Compliance, you need to sign up for an Azure subscription. Using Update Compliance shouldn’t incur any charges on your subscription. Devices are enrolled by configuring your Update Compliance Commercial ID and setting the Windows Diagnostic Data level to Basic using Group Policy, Mobile Device Management, or System Center Configuration Manager.
For more information on using Update Compliance, see Use the Update Compliance in Operations Management Suite to Monitor Windows Updates on Petri.
Don’t Put Off Updates for Too Long
Plan to make sure that feature updates get installed at some point, otherwise you will find yourself left with an unsupported version of Windows 10. And that means you will stop receiving quality updates, which include important security fixes. Microsoft has changed the support lifecycle for Windows 10 a couple of times recently, so make sure you keep up-to-date with any developments.
And if you decide to defer quality updates, keep the deferment period to a minimum because you could be leaving yourself exposed to flaws that might be exploited with little or no user interaction.
The post Managing Windows 10 Updates in a Small Businesses Environment appeared first on Petri.
Serverless from the ground up: Building a simple microservice with Cloud Functions (Part 1)
The content below is taken from the original ( Serverless from the ground up: Building a simple microservice with Cloud Functions (Part 1)), to continue reading please visit the site. Remember to respect the Author & Copyright.
Do your company’s employees rely on multiple scattered systems and siloed data to do their jobs? Do you wish you could easily stitch all these systems together, but can’t figure out how? Turns out there’s an easy way to combine these different systems in a way that’s useful, easy to create and easy to maintain—it’s called serverless microservices, and if you can code in Javascript, you can integrate enterprise software systems.
Today, we’re going to show you an easy way to build a custom content management system using Google Cloud Functions, our serverless event-driven framework that easily integrates with a variety of standard tools, APIs and Google products. We’ll teach by example, following Alice through her workday, and watch how a lunchtime conversation with Bob morphs into a custom document repository for their company. You could probably use a similar solution in your own organization, but may not know just how easy it can be, or where to start.
Alice and Bob both work at Blueprint Mobile—a fictional company that sells and repairs mobile phones. At lunch one day, Bob tells Alice how his entire morning was lost searching for a specific device manual. This is hardly surprising, since the company relies on documents scattered across Team and personal Drive folders, old file servers, and original manufacturer websites. Alice’s mind races to an image of a perfect world, where every manual is discoverable from a single link, and she convinces Bob to spend the afternoon seeing what they could build.
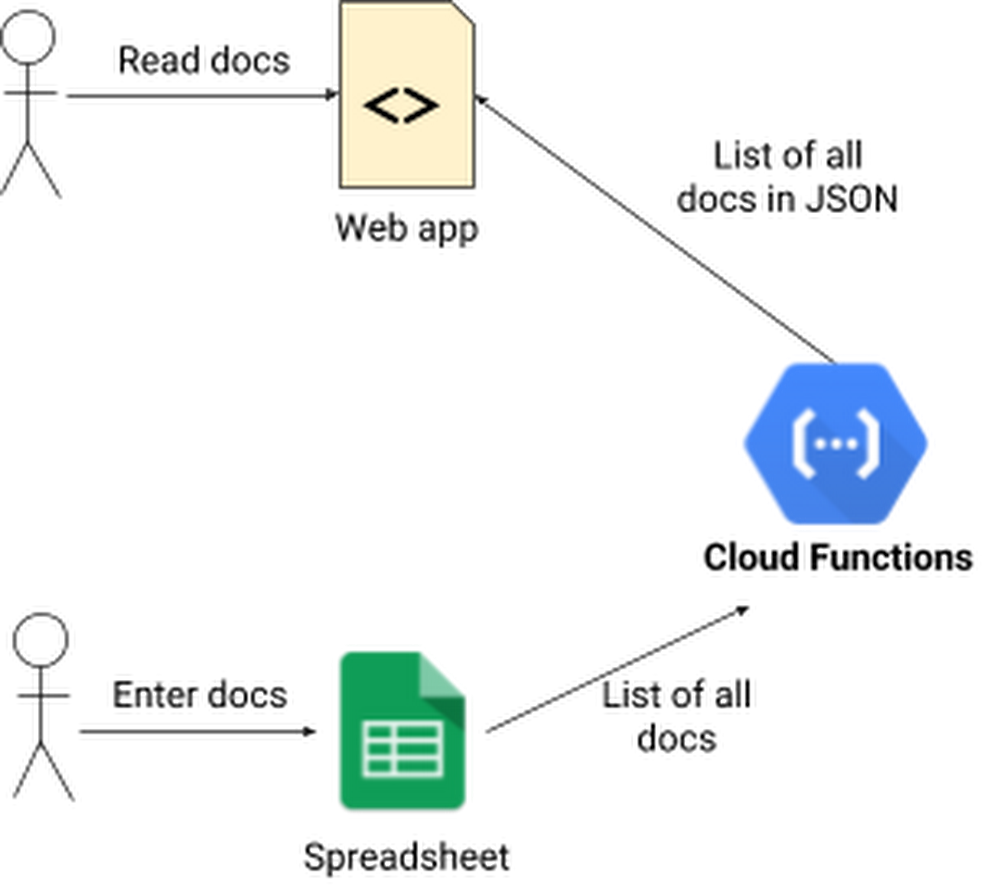
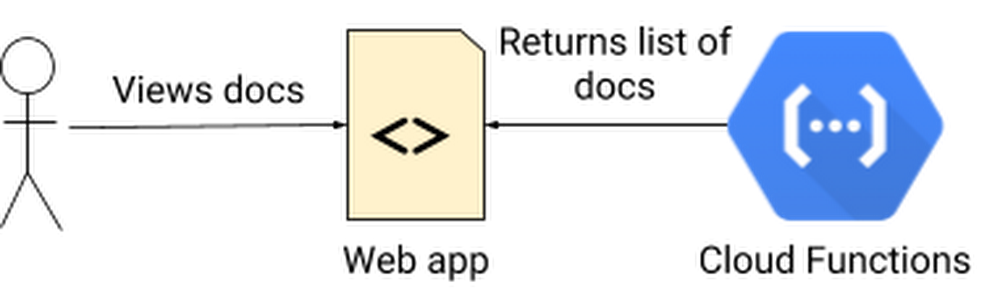
Alice’s idea is to create a URL that lists all the documents, and lets technicians use a simple web app to find the right one. Back at her desk, she pings Carol, the company’s intranet developer, to sanity-check her idea and see if it will work with the company intranet. With Carol’s help, Alice and Bob settle on this architecture:
New microservice integration with existing systems
The group gathers to brainstorm, where they decide that a microservice called handsetdocs should return a JSON array where each element is a document, belonging to a handset. They sketch out this JSON structure on a whiteboard:
Then, they decide that Bob will build a repair shop web app that will interact with Alice’s microservice like this:
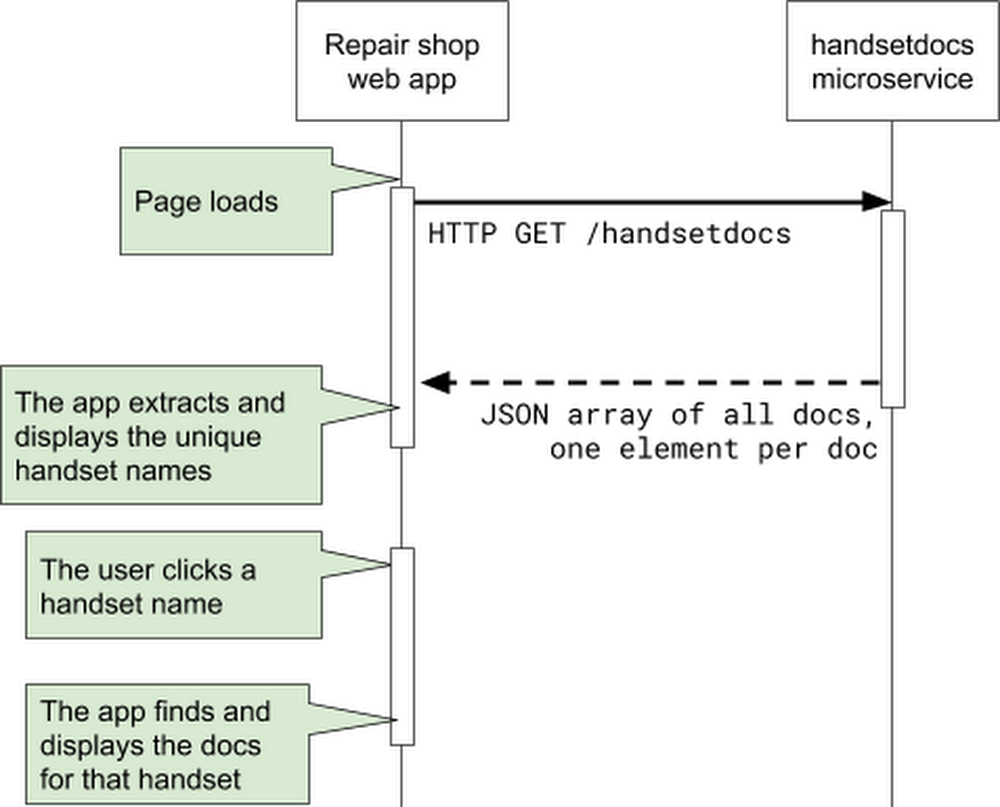
Sequence diagram for the new microservice and web app
Alice takes a photo of the whiteboard and goes back to her desk. She starts her code editor and implements the handsetdocs microservice using Cloud Functions:
This is the first code that runs when the service’s URL is accessed. The first line sets up Cross-Origin Resource Sharing (CORS), which we’ll explain in more detail later. The second line of the function calls getHandsetDocs() and returns the response to the caller. (Alice also took a note to look into IAM security later, to make sure that only her colleagues are able to access her microservice.)
Alice deploys the getHandsetDocs() function in the same file as handsetdocs above. Her first draft of the function is a simple hard-coded list of documents:
Finally, Alice reads up on Cross-Origin Resource Sharing (CORS) in Cloud Functions. CORS allows applications running on one domain to access content from another domain. This will let Bob and Carol write web pages that run on the company’s internal domain but make requests to the handsetdocs microservice running on cloudfunctions.net, Cloud Functions’ default hosting domain. You can read more about CORS at MDN.
Alice puts all three functions above in a file called index.js and deploys the handsetdocs microservice as a cloud function:
The code in getHandsetDocs() won’t win any prizes, but it allows Bob and Carol to start testing their web apps (which call the handsetdocs microservice) within an hour of their discussion.
Bob takes advantage of this useful microservice and writes the first version of the repair store web app. Its HTML consists of two empty lists. The first list will display all the handsets. When you click an entry in that list, the second list will be populated with all the documents for that handset.

The web app’s user interface
To populate each list, calls to the handsetdocs microservice are done from the app’s Javascript file. When the web page first loads, it hits the microservice to get the list of docs and lists the unique handset names in the first list of the page. When the user clicks a handset name, the docs keyed to that handset are displayed in the second list on the page.
This code solves a real business need in a fairly simple manner—Alice calls it version 0.1. The technicians now have a single source of truth for documents. Also, Carol can call the microservice from her intranet app to publish a document list that all other employees can access. In one afternoon, Alice and Bob have hopefully prevented any more lost mornings spent hunting down the right document!
Over the next few days, Bob continues to bring Alice lists of documents for the various handsets. For each new document, Alice adds a row to the getHandsetDocs() function and deploys the new version. These quick updates allow them to grow their reference list each time someone discovers another useful document. Since Blueprint Mobile only sells a small number of handsets, this isn’t too much of a burden on either Bob or Alice. But what happens if there’s a sudden surge of documents to bring into the system?
Stay tuned for next week’s installment, when Alice and Bob use Google Sheets to enable other departments to use the system.
Arm launches Neoverse, its IP portfolio for internet infrastructure hardware
The content below is taken from the original ( Arm launches Neoverse, its IP portfolio for internet infrastructure hardware), to continue reading please visit the site. Remember to respect the Author & Copyright.
Arm-based chips are ubiquitous today, but the company isn’t resting on its laurels. After announcing its ambitions for powering more high-end devices like laptops a few months ago, the company today discussed its roadmap for chips that are dedicated to internet infrastructure and that will power everything from high-performance servers to edge computing platforms, storage systems, gateways, 5G base stations and routers. The new brand name for these products is ‘Neoverse’ and the first products based on this IP will ship next year.
Arm-based chips have, of course, long been used in this space. What Neoverse is, is a new focus area where Arm itself will now invest in developing the technologies to tailor these chips to the specific workloads that come with running infrastructure services. “We’ve had a lot of success in this area,” Drew Henry, Arms’ SVP and GM for Infrastructure, told me. “And we decided to build off that and to invest more heavily in our R&D from ourselves and our ecosystem.”
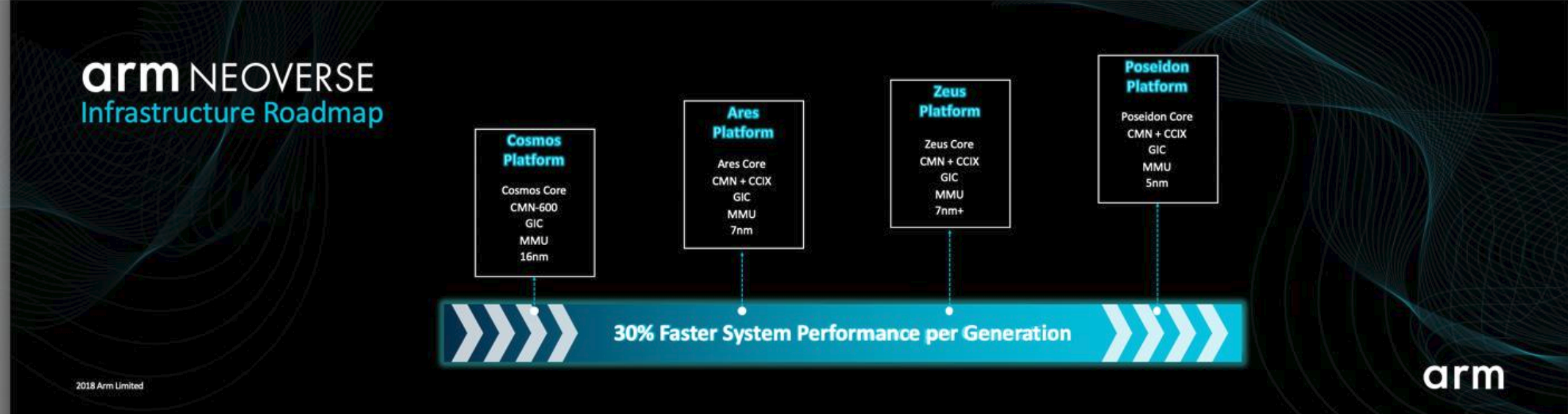
As with all Arm architectures, the actual chip manufacturers can then adapt these to their own needs. That may be a high core-count system for high-end servers, for example, or a system that includes a custom accelerator for networking and security workloads. The Neoverse chips themselves have also been optimized for the ever-changing data patterns and scalability requirements that come with powering a modern internet infrastructure.
The company has already lined up a large number of partners that include large cloud computing providers like Microsoft, silicon partners like Samsung and software partners that range from RedHat, Canonical, Suse and Oracle on the operating system side to container and virtualization players like Docker and the Kubernetes team.
Come 2019, Arm expects that Neoverse systems will feature 7nm CPUs. By 2020, it expects that will shrink to 5nm. What’s more important, though, is that every new generation of these chips, which will arrive at an annual cadence, will be 30 percent faster.
Simplifying cloud networking for enterprises: announcing Cloud NAT and more
The content below is taken from the original ( Simplifying cloud networking for enterprises: announcing Cloud NAT and more), to continue reading please visit the site. Remember to respect the Author & Copyright.
At Google Cloud, our goal is to meet you where you are and enable you to build what’s next. Today, we’re excited to announce several additions to our Google Cloud Platform (GCP) networking portfolio delivering the critical capabilities you have been asking for to help manage, secure and modernize your deployments. Here, we provide a glimpse of all these new capabilities. Stay tuned for deep dives into each of these offerings over the coming weeks.
Cloud NATBeta
Just because an application is running in the cloud, doesn’t mean you want it to be accessible to the outside world. With the beta release of Cloud NAT, our new Google-managed Network Address Translation service, you can provision your application instances without public IP addresses while also allowing them to access the internet—for updates, patching, config management, and more—in a controlled and efficient manner. Outside resources cannot directly access any of the private instances behind the Cloud NAT gateway, thereby helping to keep your Google Cloud VPCs isolated and secure.
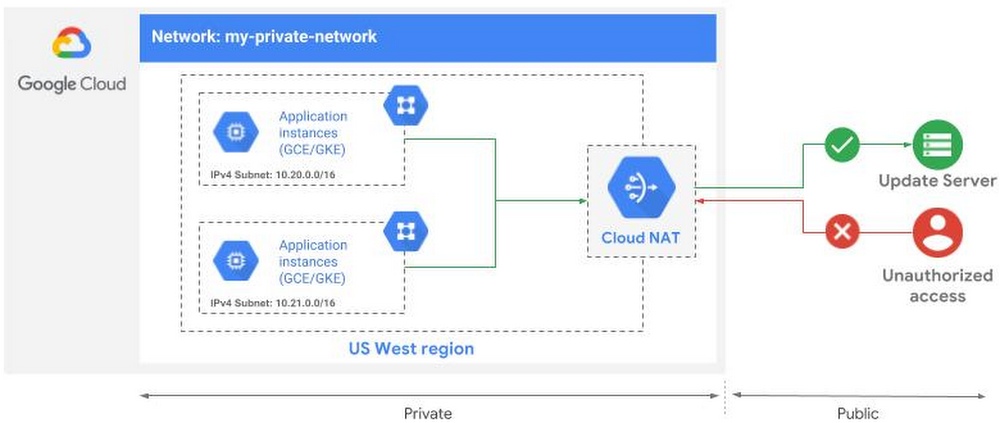
Prior to Cloud NAT, building out a highly available NAT solution in Google Cloud involved a fair bit of toil. As a fully managed offering, Cloud NAT simplifies that process and delivers several unique features:
-
Chokepoint-free design with high reliability, performance and scale, thanks to being a software-defined solution with no managed middle proxy
-
Support for both Google Compute Engine virtual machines (VMs) and Google Kubernetes Engine (containers)
-
Support for configuring multiple NAT IP addresses per NAT gateway
-
Two modes of NAT IP allocation: Manual where you have full control in specifying IPs, and Auto where NAT IPs are automatically allocated to scale based on the number of instances
-
Configurable NAT timeout timers
-
Ability to provide NAT for all subnets in a VPC region with a single NAT gateway, irrespective of the number of instances in those subnets
-
Regional high availability so that even if a zone is unavailable, the NAT gateway itself continues to be available
You can learn more about Cloud NAT here.
Firewall Rules LoggingBeta
What good are rules if you don’t know if they are being followed? Firewall Rules Logging, currently in beta, allows you audit, verify, and analyze the effects of your firewall rules. For example, it provides visibility into potential connection attempts that are blocked by a given firewall rule. Logging is also useful to determine that there weren’t any unauthorized connections allowed into an application.
Firewall log records of allowed or denied connections are reported every five seconds, providing near real-time visibility into your environment. You can also leverage the rich set of annotations as described here. As with our other networking features, you can choose to export these logs to Stackdriver Logging, Cloud Pub/Sub, or BigQuery.
Firewall Rules Logging comes on the heels of several new telemetry capabilities introduced recently including VPC Flow Logs and Internal Load Balancing Monitoring. Learn more about Firewall Rules Logging here.
Managed TLS Certificates for HTTPS load balancersBeta
Google is a big believer in using TLS wherever possible. That’s why we encourage load balancing customers to deploy HTTPS load balancers. However, manually managing TLS certificates for these load balancers can be a lot of work. We’re excited to announce the beta release of managed TLS certificates for HTTPS load balancers. With Managed Certs, we take care of provisioning root-trusted TLS certificates for you and manage their lifecycle including renewals and revocation.
Currently in beta, you can read more about Managed Certs here. Support for SSL proxy load balancers is coming soon.
New load balancing features
We invest significant resources to ensure Google Cloud remains the best place to run containerized workloads. We are excited to introduce container-native load balancing for applications running on Google Kubernetes Engine (GKE) and self-managed Kubernetes in Google Cloud. With this capability, you can program load balancers with network endpoints representing the containers and specified as IP and port pair(s) using a Google abstraction we call Network Endpoint Groups (NEGs). With NEGs, the load balancer now load balances directly to the containers, rather than to VMs, thereby avoiding one or more extra hops.
In addition to container-native load balancing, we’ve also introduced over a dozen other load balancing and CDN capabilities in the past few months, including:
-
Google managed and custom TLS policies in GA, enabling you to control TLS versions and ciphers for meeting PCI and other compliance requirements
-
QUIC support for HTTP(S) load balancers in GA, enabling you to lower latency and improve performance for your load balancers
-
HTTP/2 and gRPC from load balancer to application instances in beta. We’ve already been supporting HTTP/2 from the client to the load balancer for a while and with this feature, you can deploy HTTP/2 and gRPC from the load balancer to your backends for improved performance
-
User-defined request headers in beta, where the HTTP(S) load balancer inserts information such as client location, and Round Trip Time (RTT) into HTTP(S) requests and sends it to your backend application instances
-
Content-based health checks in beta, enabling you to specify content to be matched against the body of HTTP health check response
-
Network Tiers for Load Balancing in beta, so you can optimize the outbound traffic from your load balanced instances for performance or cost
-
Cloud Armor, a DDoS and application defense service for HTTP(S) LB
-
Cloud CDN Signed URLs in GA, enabling you to give clients temporary access to private cached content without requiring additional authorization
-
Cloud CDN Large Objects support in GA, allowing you to cache and serve video and other content up to 5TB in size
We look forward to your feedback
In short, we’ve been busy. But we’re far from done. Let us know how you plan to use these new networking services, and what capabilities you’d like to have in the future. You can reach us at [email protected]
Palm is back (sort of), and it built a tiny smartphone sidekick
The content below is taken from the original ( Palm is back (sort of), and it built a tiny smartphone sidekick), to continue reading please visit the site. Remember to respect the Author & Copyright.
When HP unceremoniously shut down Palm in 2011, it felt like the end of an era. The PDA and smartphone maker’s glory days were in the past by then, but it
well behind it, but developed a string of hits in the late 90s and early 2000s, and few names in the industry inspi… inspired as m…
REST vs. RPC: what problems are you trying to solve with your APIs?
The content below is taken from the original ( REST vs. RPC: what problems are you trying to solve with your APIs?), to continue reading please visit the site. Remember to respect the Author & Copyright.
A fairy ring is a naturally occurring circle of mushrooms that grows in forested areas or grassland. In folklore, fairy rings have magical properties and superstitious people carefully avoid disturbing them. There’s an old joke about the farmer who was asked why he went to such lengths to avoid ploughing up fairy rings. He replied, “because I’d be a fool if I didn’t.”
Many people would say the same thing about why they build APIs. In fact, it is important to think about the fundamental problem you are trying to solve with your API because the style of API you create and the technologies you choose should depend on your answer.
Following procedure
Procedures, also called functions, have been the dominant construct for organizing computer code ever since FORTRAN II introduced the concept in 1958. All mainstream modern programming languages that are used to produce and consume APIs—for example Java, Javascript, Python, Golang, C/C++ and PHP—use procedures as their central organizing construct1, so it is not surprising that procedures have also been the dominant model for designing and implementing distributed APIs for decades, in the form of Remote Procedure Calls (RPC).
If you ask most software developers why they define and build APIs, they are likely to explain that they have an application that is implemented as multiple distributed components, and those components call each other’s APIs for the complete application to function. They may also say that they are implementing the API of a service that is used by multiple applications.
When developers design APIs to solve these kinds of problems, the solution characteristics they will typically prioritize are ease of programming for both the client and the server, and efficiency of execution. RPC is a good match for these priorities. RPC fits very well with the thought processes and skills of programmers on both the producer and consumer side of an API. Calling a remote procedure is usually syntactically the same as calling a normal programming language procedure, and learning the procedures of a remote API is very similar to learning a new programming library. RPC implementations also tend to be efficient—the data that is passed between the client and the server is usually encoded in binary formats, and the RPC style encourages relatively small messages (although some care has to be taken to avoid overly chatty interactions).
If RPC is such a good fit with the rest of software development, why is there another popular model for APIs—REST—and why is there so much controversy about which to use?
Unsolved problems
Communicating between two components in a distributed system is largely a solved problem—there are many successful technologies available for different levels, like TCP for basic data transfer, RPC or HTTP as programming models, and various algorithms that deal with consistency of state in distributed systems. That doesn’t mean it is easy to develop distributed systems, but the problems and their solutions are reasonably well-known.
By contrast, there are unsolved problems in software that have huge economic impact. Two of these are the fact that almost all software is extremely difficult to change, and that software systems are difficult to integrate. Both problems are relevant to the discussion of APIs because they help motivate an alternative model to RPC.
Software is hard to change
Unless you are working in a startup that is only a few months old, it is almost certain that one of your organization’s most significant problems is dealing with a legacy of software that no longer fits its current needs or directions. In almost all cases, this software is too valuable to abandon, and too difficult to change. It is likely that a very large part of the organization’s development budget is consumed by this reality.
One of the primary reasons that software is difficult to change is that basic assumptions are propagated through code from procedure to procedure. Some of those assumptions are technical assumptions, like what storage technologies are being used or what error or failure conditions are possible, while other assumptions concern the basic use-cases of the application, like which concepts are used with which others in what ways.
It isn’t easy to characterize exactly why software is so brittle, but unless you’re new to software development, you’ve almost certainly found yourself in the situation where relatively straightforward-seeming technical or functional changes prove to be extremely difficult to make, because assumptions in the code are broadly distributed and hence difficult to change.
If you have been a technical leader in software for a while, you have probably been through multiple efforts to improve software flexibility through better modularity without seeing much fundamental improvement—software remains stubbornly rigid and difficult to change. One of the lessons we can take from this is that technical and business assumptions pass through procedure boundaries like water through a sieve. This is largely true of remote procedures as well as local procedures.
Integration is a major opportunity and problem
When you first start writing software to automate a particular problem domain, the majority of the software you write will focus on automating basic features and workflows. As the software matures, more value comes from integrating and augmenting existing systems, rather than building brand new ones. For example, many companies have development initiatives to create a more integrated experience for customers interacting with their different systems, or to help the business see an overall picture of its customers, suppliers, or partners across multiple systems.
When businesses open up APIs to their systems, they sometimes have a purely tactical goal, like enabling the development of a mobile application. More visionary businesses, however, open up APIs to clients and partners so that they can integrate with their data and systems in innovative ways. In other words, the primary motivation for many businesses in creating APIs is to enable third parties to create integration applications of which their systems can be a part.
For example, both travel and expense reporting applications are major feats of integration bringing together reservations of multiple services (transport, lodging, food, entertainment), approvals, financial records and so on, all across different companies. Anyone who has worked on an integration project knows that they are hard. One difficulty is the sheer variability of the interfaces and technologies that have to be integrated. Another is that many of the systems don’t even have quality APIs.
REST APIs, and how they can help
The global success of the world-wide web has led to a lot of interest in an alternative model for APIs—REST.
REST itself is a description of the design principles that underpin HTTP and the world-wide web. But because HTTP is the only commercially important REST API, we can mostly avoid discussing REST and just focus on HTTP. This substitution is useful because there is a lot of confusion and variability in what people think REST means in the context of APIs, but there is much greater clarity and agreement on what HTTP itself is. The HTTP model is the perfect inverse of the RPC model—in the RPC model, the addressable units are procedures, and the entities of the problem domain are hidden behind the procedures. In the HTTP model, the addressable units are the entities themselves and the behaviors of the system are hidden behind the entities as side-effects of creating, updating, or deleting them.
One of the remarkable characteristics of the world-wide web is that every address on the web exposes exactly the same API—HTTP. (In the REST description of HTTP, this is called the “uniform interface constraint.”) This means that to navigate the entire world-wide web, you only need to know a single API—this fact is what made possible the development of the web browser. Unfortunately, many of the APIs that claim to be RESTful layer a lot of proprietary concepts on top of HTTP. Essentially, they invent their own API and use HTTP as a lower-level transport layer, rather than using HTTP directly as it was designed. In fact, there’s so much variability in the way that people use the term REST in the context of APIs that it’s difficult to know what they mean by it unless you know them well.
Because HTTP is already so widely known, there’s a lot less to learn about an API that uses HTTP directly than an RPC one. Learning an RPC API is very similar to learning a programming library. The interface of a programing library is typically made up of many procedure signatures that each have to be learned, and there’s little commonality or predictability between procedures in different libraries (and often not even within the same library).
By contrast, learning an API that uses HTTP directly is like learning a database schema. Every database managed by the same database management system, whether it’s Postgres, MySQL, or Spanner, has exactly the same API, so you only have to learn that API once. For an individual database, you only have to learn the tables and their columns2, and their meanings; compared to a typical programming library, there is much less detail to learn in a database. An API that uses HTTP directly, like a database, is mostly defined by its data model. What about querying, you ask? It’s true that complex queries—beyond simple create, retrieve, update and delete—are important in APIs as they are in databases, and that HTTP does not give us a standard query syntax for its API in the way that a database management system does, so there is typically more to learn that is specific to an HTTP API than to a database. But it’s still much less than a corresponding RPC API, and the query syntax exposed by most APIs is much simpler than a database management system’s. (One exception might be if the API includes something like GraphQL, in which case you have the compensating benefit that the query language is the same for many APIs.)
If an API uses HTTP simply and directly, it will only have to document three or four things. (And if an API requires you to read a lot of documentation to learn how to use it, then it is probably not using HTTP as the uniform API.) The four elements of an HTTP API are:
-
A limited number of fixed, well-known URLs. These are analogous to the names of the tables in a database. For optional extra credit, make all the fixed URLs discoverable from a single one.
-
The information model of each of its resources, i.e., the properties of each type. This is analogous to the columns of a database table. Relationships between entities are expressed as URL-valued properties.
-
Some indication of the supported subset of HTTP, since few APIs implement every feature of the protocol.
-
Optionally, some sort of query syntax that enables efficient access to resource data without fetching whole resources one at a time. API designers are endlessly creative in how they allow queries to be encoded in URLs—my favorite option is to use only a query string appended to the well-known URLs defined in 1. above.
If the API is using HTTP properly, clients already know everything else they need to know because they already know HTTP.
How HTTP helps with integration
It should be obvious by now that it would be significantly easier to integrate applications if all APIs just used HTTP simply and directly, because then the application only has to know HTTP, rather than a lot of different APIs. The data model exposed by each API may be different, but the mechanisms for accessing and changing the data will be the same for all of them.
An essential part of the problem in most integration applications is defining relationships between entities that are maintained in different systems. For example, flight reservations, hotel reservations, car reservations, credit card payments, and approvals all need to be linked together to manage a trip reservation or its reimbursement. In order to link these entities together, each must have a clear identity by which it can be referenced outside of the application in which it is housed. The world-wide web standards define the concept of a URL, an identifier for a resource that is valid everywhere (hence the name world-wide), not just locally in the API of a particular system. This is very helpful for integration applications because the problem is already solved for all entities that are accessed by APIs that use HTTP directly. By contrast, in RPC-based APIs the identity of an entity is almost always expressed in a form that is local to the application that houses it, putting the burden onto the developer to define an identity for each entity that is valid outside that application.
How HTTP helps make software easier to change
What about the difficulty of modifying software—can HTTP/REST help there too? We saw that the RPC model makes it very simple and direct for programmers to write a procedure in one program and call it from another. This is one of the characteristics that makes RPC so popular, but it also makes it easy for technology and use-case assumptions to flow easily from one application to the other, thereby coupling the two and making the system brittle.
HTTP/REST helps break that flow of assumptions, by forcing an intermediate translation from implementation procedures to an entity model. Procedures are no longer exposed directly at the interface to be called remotely; instead, API developers construct an entity model in between that disconnects the two sides. The entity-oriented model is not arbitrary; it is the conceptual data model of the problem domain as viewed by the client. It will likely have some relationship to an underlying storage data model, but is usually simpler and more abstract. How effectively the API entity model decouples the caller from the callee depends a lot on the skill of the model’s designers, but the mere presence of the translation layer increases the chances of meaningful decoupling.
In my experience, it is also much easier to institutionalize review and oversight of an API that is based on entities. When an API is based on remote procedures, it tends to grow organically as one procedure after another is added to handle specific needs. When an API is realized as an entity model, there is less tendency for unbridled organic growth, because entity models typically have a greater degree of coherence and overall structure. Evolving an API based on an entity model requires you to explicitly add a new type, property, or relationship to the model, which typically forces you to think about how the addition fits with the overall model. I have no doubt there are some well-governed RPC APIs where each procedure is one tile in a carefully-drawn mosaic, and no tile is ever added or changed without considering its impact on the whole picture. But in my experience this sort of coherence is more difficult to achieve for RPC APIs, and much less common.
No gain without pain
It’s true that using entity-based APIs rather than procedures can introduce additional cost in the form of design and implementation complexity and processing overhead. Whether or not this cost is justified depends on your API goals. If efficiency is your first priority, RPC may be a better choice.
There is also a shortage of people who understand how to design good HTTP/REST APIs. Unfortunately, we see many examples of APIs that attempt to adopt the entity-oriented HTTP/REST style, but fail to realize all the benefits because they do not follow the model consistently. Some common mistakes are:
-
Using “local identifiers” rather than URLs to encode references between entities. If an API requires a client to substitute a variable in a URI template to form the URL of a resource, it has already lost an important part of the value of HTTP’s uniform interface. Constructing URLs that encode queries is the only common use for URI templates that is compatible with the idea of HTTP as a uniform interface.
-
Putting version identifiers in all URLs. URLs that include version identifiers are not bad in and of themselves, but they are useless for encoding references between entities. If all your URLs include version identifiers, you are probably using local identifiers instead of URLs to represent relationships, which is the first mistake.
-
Confusing identity with lookup. HTTP-based APIs depend on the fact that each entity is given an identity in the form of URI that is immutable and eternal. In many APIs it is also useful to be able to reference entities by their names and/or other mutable characteristics, like position in a hierarchy. It is important not to confuse an entity’s own URI with alias URIs used to reference the same entity via a lookup on its name or other mutable characteristics.
JSON’s part in the story
HTTP does not mandate a particular data format, but JSON is by far the most popular. JSON was originally designed to be a good match for the way JavaScript represents data, but all mainstream programming languages support it. JSON is a relatively abstract format that is generally free of technology-specific constraints. JSON is also a text format, making it simple to understand and debug. These are good characteristics if ease of adoption and change are your primary goals, but less optimal if you’re aiming for efficient communication between tightly-coupled components.
Programmers using statically-typed languages like Java, Golang or C++ will commonly push to constrain the ways in which JSON is used to fit with the ways in which their programming language prefers to process it. Whether or not you should accede to their wishes depends on your goals for the API.
Pick the API style that fits your goals
My message is not that HTTP/REST is better than RPC. If the goal of your API is to enable communication between two distributed components that you own and control, and processing efficiency is a major concern, then I think that RPC in general and gRPC in particular might be excellent choices for designing and implementing your API.
However, if your primary objective is to make your software more malleable by breaking it down into components that are better isolated from each others’ assumptions, or if your purpose is to open up your systems for future integration by other teams, then you should focus your efforts on HTTP/JSON APIs—provided you learn to use HTTP as simply and directly as possible. That way, anyone who knows HTTP from the standards documents or a multitude of less formal tutorials will be able to use your API, with no more documentation than a description of the API’s identity model and a little bit of query syntax. I think that’s a worthy goal.
For more on API design, read the eBook, “Web API Design: The Missing Link.”
1. Special-purpose languages like HTML, CSS or SQL that do not have functions or procedures or don’t use them as a central concept are sometimes classified as “programming languages”, but they are not used to implement APIs, so they are not relevant to this discussion.
2. If your database management system is a NoSQL database like MongoDB, CouchDB or Cassandra, then the vocabulary here is a bit different, but the idea is the same.
How Event-Based Retention Works for Office 365
The content below is taken from the original ( How Event-Based Retention Works for Office 365), to continue reading please visit the site. Remember to respect the Author & Copyright.


Office 365 Data Governance Takes Care of Events
Office 365 classification labels have properties that dictate how content is processed by Office 365 when specific conditions occur. The properties include a retention action and retention period. Together, when users assign classification labels to content, the retention action control whether Office 365 keeps items for the period or removes them after the period elapses. The newest action requires a manual review of content before it can be removed (manual disposition).
Up to now, classification labels use date-based retention where the last modified or created date governs the calculation when a retention period expires to invoke the retention action. Microsoft is adding event-based retention to increase the flexibility of Office 365 data governance.
Event Driven Retention
Event-based retention recognizes that circumstances arise that affect how content is retained. For example, the completion of a project, termination of a contract, or when an employee leaves the organization. When these events occur, the organization might wish to make sure to keep documents for a set period or make sure that certain content is removed after that period expires.
Office 365 Events
An event commences when an administrator creates it, following which background processes look for content relating to the event and take the retention action defined in the label. The retention action can be to keep or remove items, or to mark them for manual disposition. In all cases, the countdown for the retention period starts when the event commences rather than the date when items were created or last modified.
The current implementation concentrates on documents in SharePoint and OneDrive for Business sites. Although Exchange content can be included in the processing invoked when an event happens, Microsoft will make it easier to associate email with an event in the future.
Processing Event-Based Retention
Because it depends on something happening rather than the passing of time, event-based retention is more complex than date-based retention. To start the process, you create a new classification label and select “an event” as the decision point for the retention period rather than the usual “date created” or “date modified” as used with other classification labels.
You also select an event type to associate with the label. An event is something like, the expiration of a contract or the departure of an employee or any other common occurrence in the life of a business. Office 365 includes a set of pre-packaged event types, but you can create new event types if needed.
Figure 1 shows the settings for a label called “Contractual Information.” The fact that this label is based on an event is obvious. When the event occurs, Office 365 keeps the content for 7 days and then triggers a manual disposition review. The selected event is “Expiration or termination of contacts and agreements.”


Figure 1: Settings for a label tied to an event (image credit: Tony Redmond)
After saving the label, publish it in a label policy to make the label available to end users. After an hour or so, the label is available to SharePoint and OneDrive for Business. It takes a little longer for the label to appear in Exchange.
Users Line up the Event
Users apply the label to content that they want to link with the event. For example, they might look for the set of documents belonging to a contract and apply the label to those documents. When they apply the label, users also give a value to a field called “Asset ID,” which is part of the standard SharePoint Online schema.
A classification label for an event type can be used with many different events, so a mechanism is necessary to isolate the content belonging to a specific event. The Asset ID is used to identify individual projects, tasks, or other entities. For instance, if the event deals with the departure of an employee, the Asset ID might hold the employee’s number. It is critical that the Asset ID is populated correctly because this is the value used to find content associated with an event.
Figure 2 shows how to apply the label and Asset ID to a document in a SharePoint Online library.

Figure 2: Adding an event label to document properties (image credit: Tony Redmond)
Searching for Content Linked to an Event.
You can find out what items are stamped for a specific event by using SharePoint search, Delve, or Office 365 content searches using the complianceassetid tag. Figure 3 shows how to use the search complianceassetid:PK1 to find documents linked to a specific project. Like any property added to documents, it takes a little time before these identifiers are in indexed and useful for discovery.

Figure 3: Using an Asset ID to find documents (image credit: Tony Redmond)
The Event Happens
When an event occurs, like an employee leaving or a contract reaching its end, the administrator goes to Events under Data Governance in the Security and Compliance Center and creates a new event. They then select what kind of event to use or choose to create an event for a label that uses event-based retention. Finally, they input the associated Asset ID (for SharePoint and OneDrive items) or keywords to locate Exchange items (Figure 4), together with the date the event happened.

Figure 4: Defining how to find items for an event (image credit: Tony Redmond)
When a new event is saved, background processes look for content matching the event in SharePoint, OneDrive, and Exchange. It can take up to a week before the background processes find all matching content across Office 365 workloads.
As items are found, Office 365 applies the retention action and period specified in the label to the items and normal retention processing begins. For instance, if the label states that items should be kept for five years, Office 365 keeps the items for five years after the event date.
Events Coming Soon
Once created, you cannot update or remove an event. For this reason, you should be sure that everything is ready to invoke an event. In addition, once you associate a label with an event, you cannot change the label to associate it with a different event.
Like everything to do with data governance, it is important that you understand what events occur for business processes within the company to understand whether event-based labels are useful to you.
Follow Tony on Twitter @12Knocksinna.
Want to know more about how to manage Office 365? Find what you need to know in “Office 365 for IT Pros”, the most comprehensive eBook covering all aspects of Office 365. Available in PDF and EPUB formats (suitable for iBooks) or for Amazon Kindle.
The post How Event-Based Retention Works for Office 365 appeared first on Petri.