




The content below is taken from the original ( What happened on the Internet during the Facebook outage), to continue reading please visit the site. Remember to respect the Author & Copyright.
It’s been a few days now since Facebook, Instagram, and WhatsApp went AWOL and experienced one of the most extended and rough downtime periods in their existence.
When that happened, we reported our bird’s-eye view of the event and posted the blog Understanding How Facebook Disappeared from the Internet where we tried to explain what we saw and how DNS and BGP, two of the technologies at the center of the outage, played a role in the event.
In the meantime, more information has surfaced, and Facebook has published a blog post giving more details of what happened internally.
As we said before, these events are a gentle reminder that the Internet is a vast network of networks, and we, as industry players and end-users, are part of it and should work together.
In the aftermath of an event of this size, we don’t waste much time debating how peers handled the situation. We do, however, ask ourselves the more important questions: “How did this affect us?” and “What if this had happened to us?” Asking and answering these questions whenever something like this happens is a great and healthy exercise that helps us improve our own resilience.
Today, we’re going to show you how the Facebook and affiliate sites downtime affected us, and what we can see in our data.
1.1.1.1
1.1.1.1 is a fast and privacy-centric public DNS resolver operated by Cloudflare, used by millions of users, browsers, and devices worldwide. Let’s look at our telemetry and see what we find.
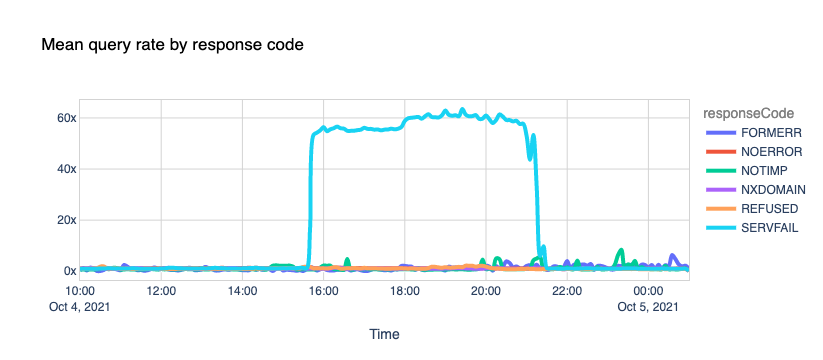
First, the obvious. If we look at the response rate, there was a massive spike in the number of SERVFAIL codes. SERVFAILs can happen for several reasons; we have an excellent blog called Unwrap the SERVFAIL that you should read if you’re curious.
In this case, we started serving SERVFAIL responses to all facebook.com and whatsapp.com DNS queries because our resolver couldn’t access the upstream Facebook authoritative servers. About 60x times more than the average on a typical day.
If we look at all the queries, not specific to Facebook or WhatsApp domains, and we split them by IPv4 and IPv6 clients, we can see that our load increased too.
As explained before, this is due to a snowball effect associated with applications and users retrying after the errors and generating even more traffic. In this case, 1.1.1.1 had to handle more than the expected rate for A and AAAA queries.
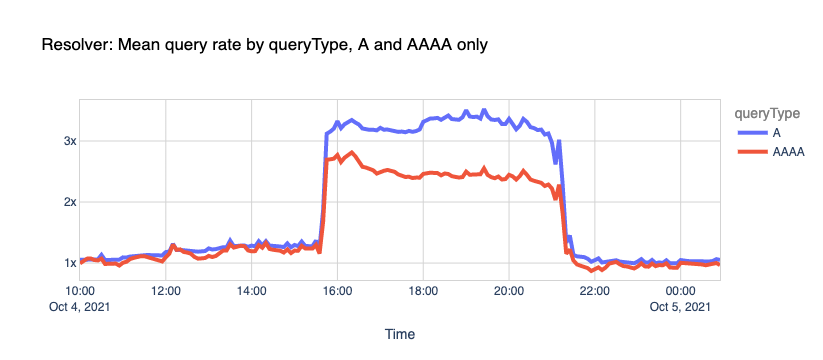
Here’s another fun one.
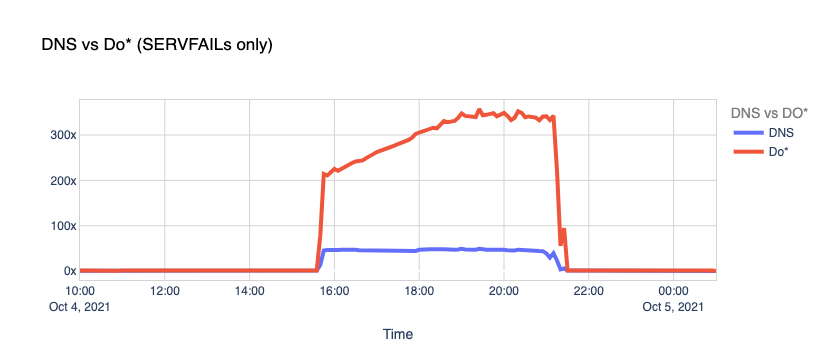
DNS vs. DoT and DoH. Typically, DNS queries and responses are sent in plaintext over UDP (or TCP sometimes), and that’s been the case for decades now. Naturally, this poses security and privacy risks to end-users as it allows in-transit attacks or traffic snooping.
With DNS over TLS (DoT) and DNS over HTTPS, clients can talk DNS using well-known, well-supported encryption and authentication protocols.
Our learning center has a good article on “DNS over TLS vs. DNS over HTTPS” that you can read. Browsers like Chrome, Firefox, and Edge have supported DoH for some time now, WAP uses DoH too, and you can even configure your operating system to use the new protocols.
When Facebook went offline, we saw the number of DoT+DoH SERVFAILs responses grow by over x300 vs. the average rate.
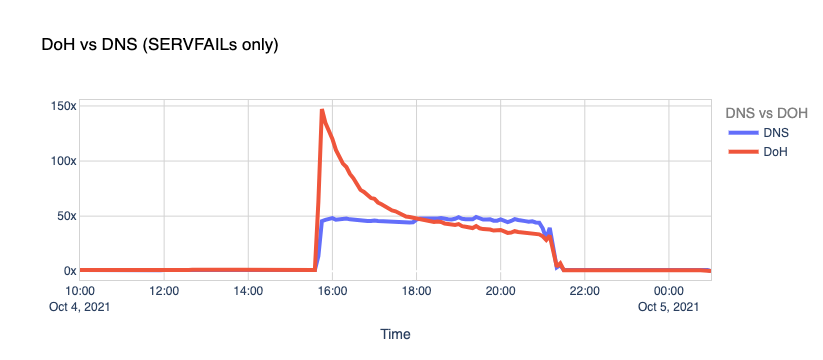
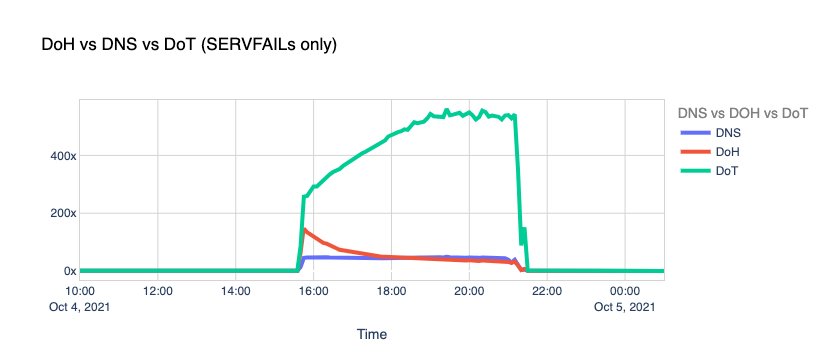
So, we got hammered with lots of requests and errors, causing traffic spikes to our 1.1.1.1 resolver and causing an unexpected load in the edge network and systems. How did we perform during this stressful period?
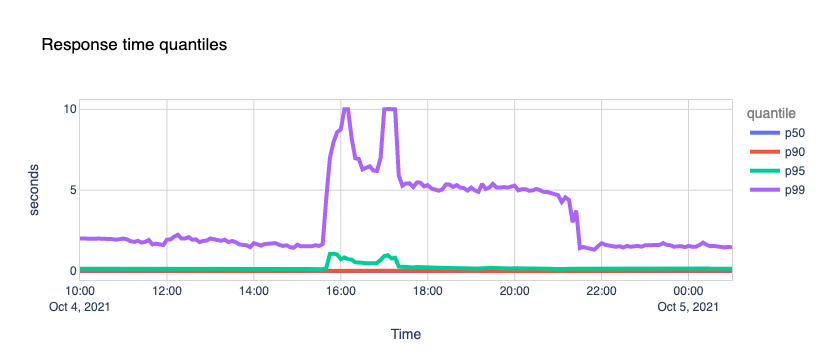
Quite well. 1.1.1.1 kept its cool and continued serving the vast majority of requests around the famous 10ms mark. An insignificant fraction of p95 and p99 percentiles saw increased response times, probably due to timeouts trying to reach Facebook’s nameservers.
Another interesting perspective is the distribution of the ratio between SERVFAIL and good DNS answers, by country. In theory, the higher this ratio is, the more the country uses Facebook. Here’s the map with the countries that suffered the most:
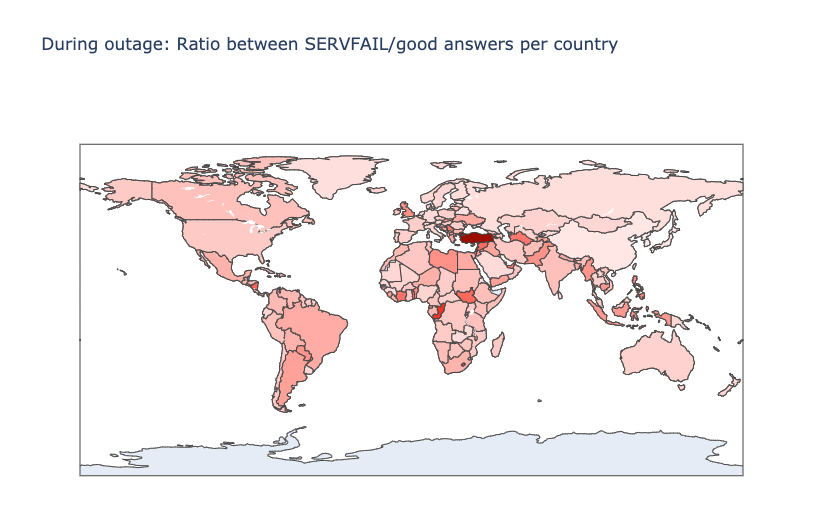
Here’s the top twelve country list, ordered by those that apparently use Facebook, WhatsApp and Instagram the most:
| Country | SERVFAIL/Good Answers ratio |
|---|---|
| Turkey | 7.34 |
| Grenada | 4.84 |
| Congo | 4.44 |
| Lesotho | 3.94 |
| Nicaragua | 3.57 |
| South Sudan | 3.47 |
| Syrian Arab Republic | 3.41 |
| Serbia | 3.25 |
| Turkmenistan | 3.23 |
| United Arab Emirates | 3.17 |
| Togo | 3.14 |
| French Guiana | 3.00 |
Impact on other sites
When Facebook, Instagram, and WhatsApp aren’t around, the world turns to other places to look for information on what’s going on, other forms of entertainment or other applications to communicate with their friends and family. Our data shows us those shifts. While Facebook was going down, other services and platforms were going up.
To get an idea of the changing traffic patterns we look at DNS queries as an indicator of increased traffic to specific sites or types of site.
Here are a few examples.
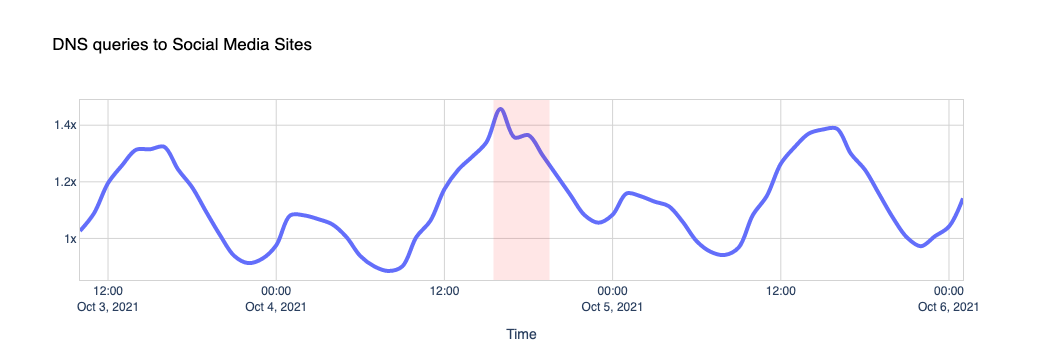
Other social media platforms saw a slight increase in use, compared to normal.
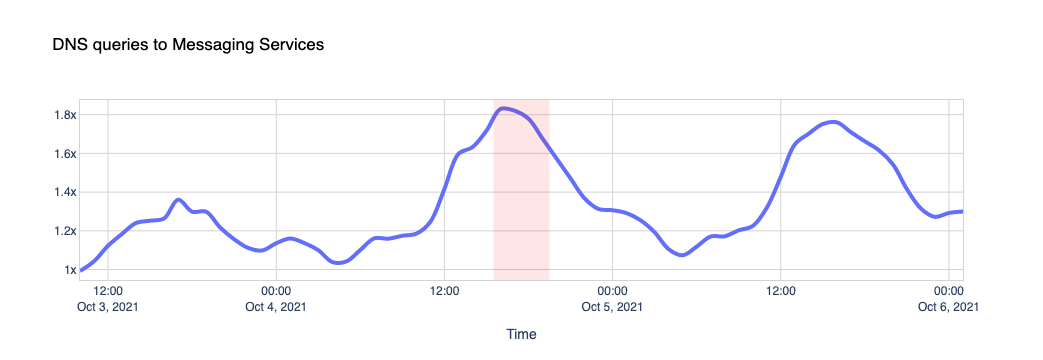
Traffic to messaging platforms like Telegram, Signal, Discord and Slack got a little push too.
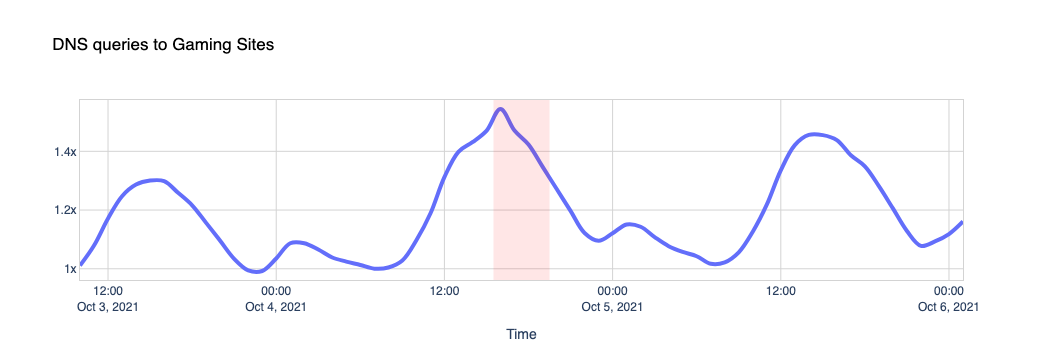
Nothing like a little gaming time when Instagram is down, we guess, when looking at traffic to sites like Steam, Xbox, Minecraft and others.
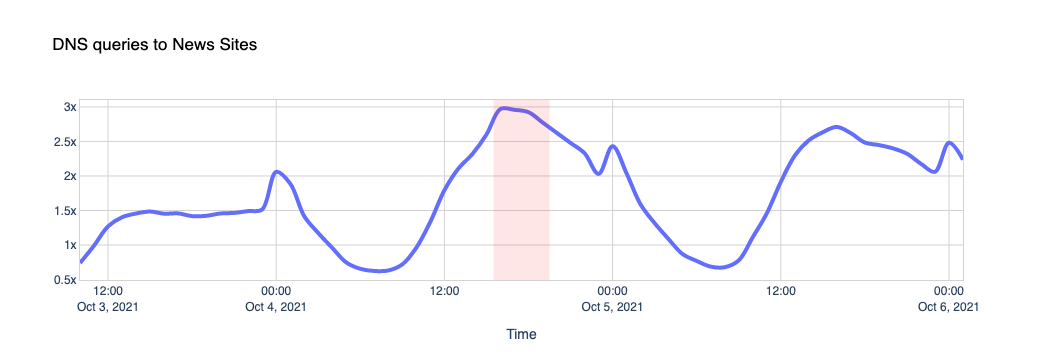
And yes, people want to know what’s going on and fall back on news sites like CNN, New York Times, The Guardian, Wall Street Journal, Washington Post, Huffington Post, BBC, and others:
Attacks
One could speculate that the Internet was under attack from malicious hackers. Our Firewall doesn’t agree; nothing out of the ordinary stands out.
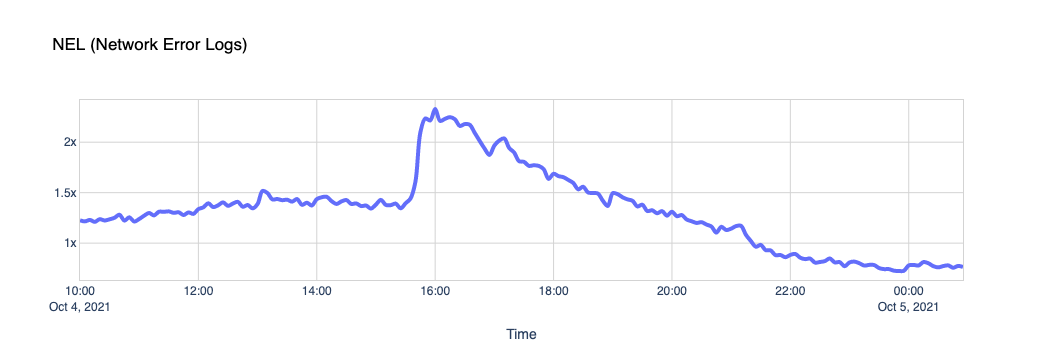
Network Error Logs
Network Error Logging, NEL for short, is an experimental technology supported in Chrome. A website can issue a Report-To header and ask the browser to send reports about network problems, like bad requests or DNS issues, to a specific endpoint.
Cloudflare uses NEL data to quickly help triage end-user connectivity issues when end-users reach our network. You can learn more about this feature in our help center.
If Facebook is down and their DNS isn’t responding, Chrome will start reporting NEL events every time one of the pages in our zones fails to load Facebook comments, posts, ads, or authentication buttons. This chart shows it clearly.
WARP
Cloudflare announced WARP in 2019, and called it “A VPN for People Who Don’t Know What V.P.N. Stands For” and offered it for free to its customers. Today WARP is used by millions of people worldwide to securely and privately access the Internet on their desktop and mobile devices. Here’s what we saw during the outage by looking at traffic volume between WARP and Facebook’s network:
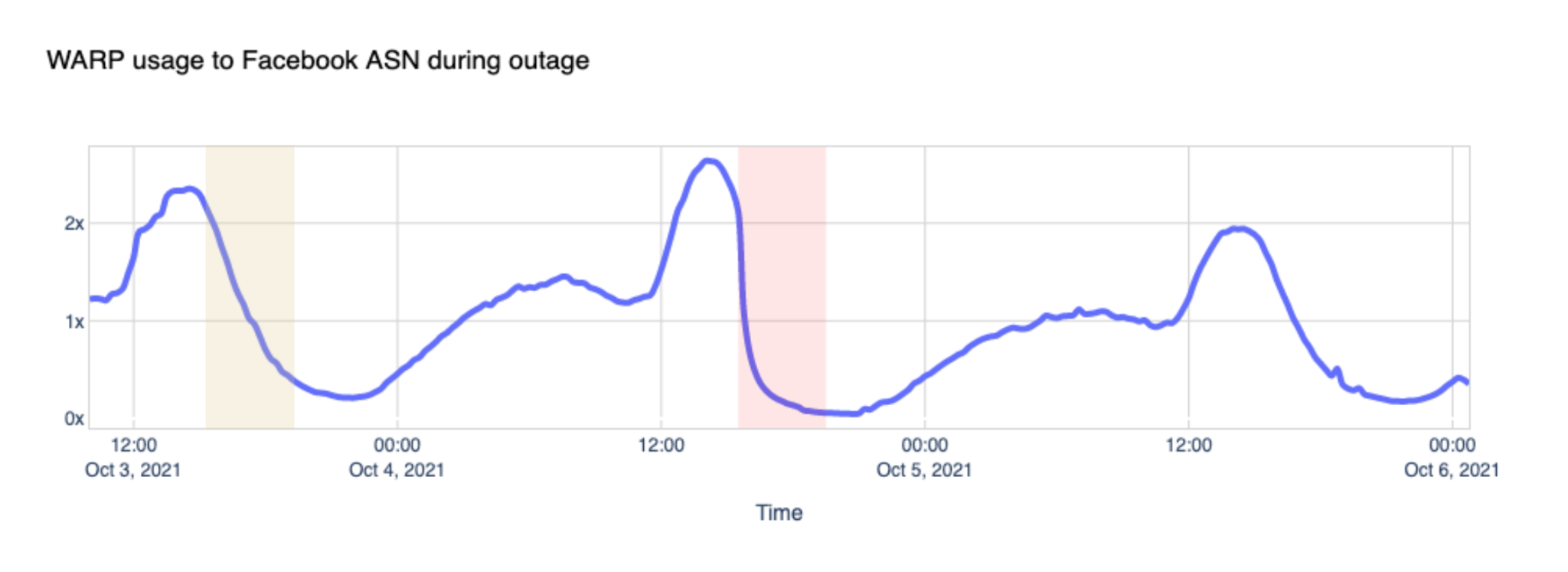
You can see how the steep drop in Facebook ASN traffic coincides with the start of the incident and how it compares to the same period the day before.
Our own traffic
People tend to think of Facebook as a place to visit. We log in, and we access Facebook, we post. It turns out that Facebook likes to visit us too, quite a lot. Like Google and other platforms, Facebook uses an army of crawlers to constantly check websites for data and updates. Those robots gather information about websites content, such as its titles, descriptions, thumbnail images, and metadata. You can learn more about this on the “The Facebook Crawler” page and the Open Graph website.
Here’s what we see when traffic is coming from the Facebook ASN, supposedly from crawlers, to our CDN sites:
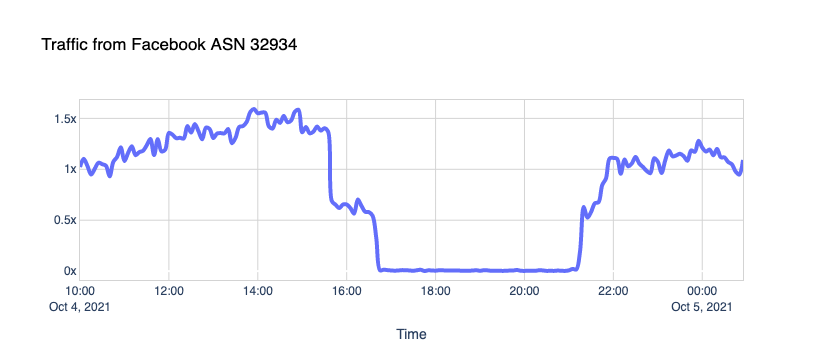
The robots went silent.
What about the traffic coming to our CDN sites from Facebook User-Agents? The gap is indisputable.
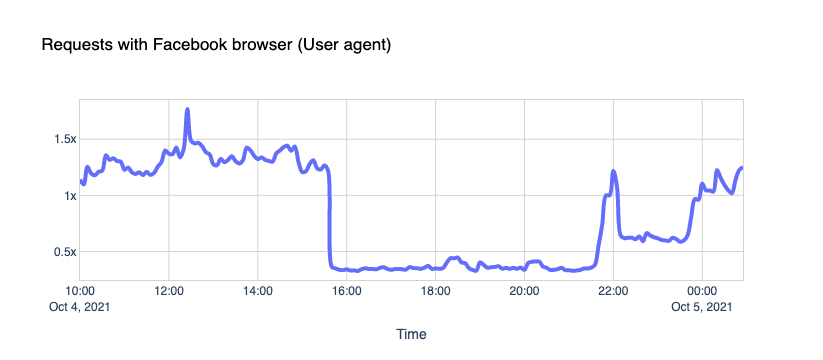
We see about 30% of a typical request rate hitting us. But it’s not zero; why is that?
We’ll let you know a little secret. Never trust User-Agent information; it’s broken. User-Agent spoofing is everywhere. Browsers, apps, and other clients deliberately change the User-Agent string when they fetch pages from the Internet to hide, obtain access to certain features, or bypass paywalls (because pay-walled sites want sites like Facebook to index their content, so that then they get more traffic from links).
Fortunately, there are newer, more secure, and privacy-centric standards emerging like User-Agent Client Hints.
Core Web Vitals
Core Web Vitals are the subset of Web Vitals, an initiative by Google to provide a unified interface to measure real-world quality signals when a user visits a web page. Such signals include Largest Contentful Paint (LCP), First Input Delay (FID), and Cumulative Layout Shift (CLS).
Weuse Core Web Vitals with our privacy-centric Web Analytics product and collect anonymized data on how end-users experience the websites that enable this feature.
One of the metrics we can calculate using these signals is the page load time. Our theory is that if a page includes scripts coming from external sites (for example, Facebook “like” buttons, comments, ads), and they are unreachable, its total load time gets affected.
We used a list of about 400 domains that we know embed Facebook scripts in their pages and looked at the data.
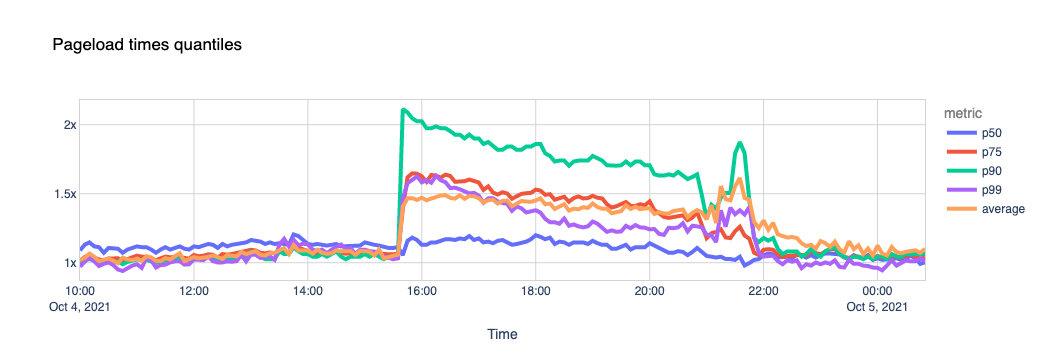
Now let’s look at the Largest Contentful Paint. LCP marks the point in the page load timeline when the page’s main content has likely loaded. The faster the LCP is, the better the end-user experience.
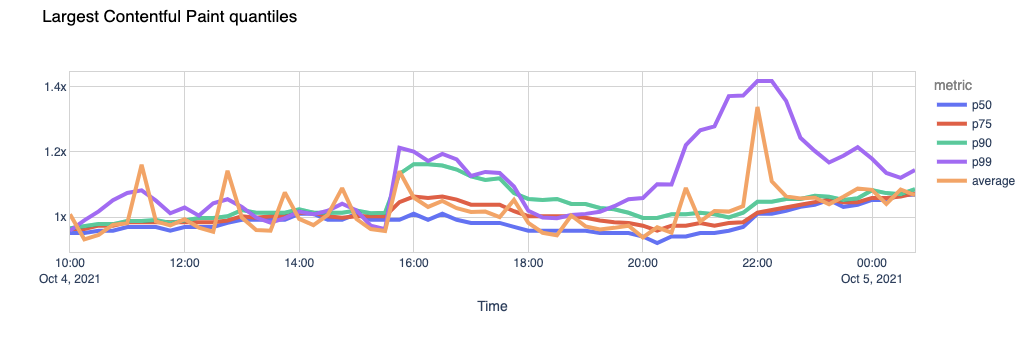
Again, the page load experience got visibly degraded.
The outcome seems clear. The sites that use Facebook scripts in their pages took 1.5x more time to load their pages during the outage, with some of them taking more than 2x the usual time. Facebook’s outage dragged the performance of some other sites down.
Conclusion
When Facebook, Instagram, and WhatsApp went down, the Web felt it. Some websites got slower or lost traffic, other services and platforms got unexpected load, and people lost the ability to communicate or do business normally.