The content below is taken from the original ( The History of the URL), to continue reading please visit the site. Remember to respect the Author & Copyright.

On the 11th of January 1982 twenty-two computer scientists met to discuss an issue with ‘computer mail’ (now known as email). Attendees included the guy who would create Sun Microsystems, the guy who made Zork, the NTP guy, and the guy who convinced the government to pay for Unix. The problem was simple: there were 455 hosts on the ARPANET and the situation was getting out of control.
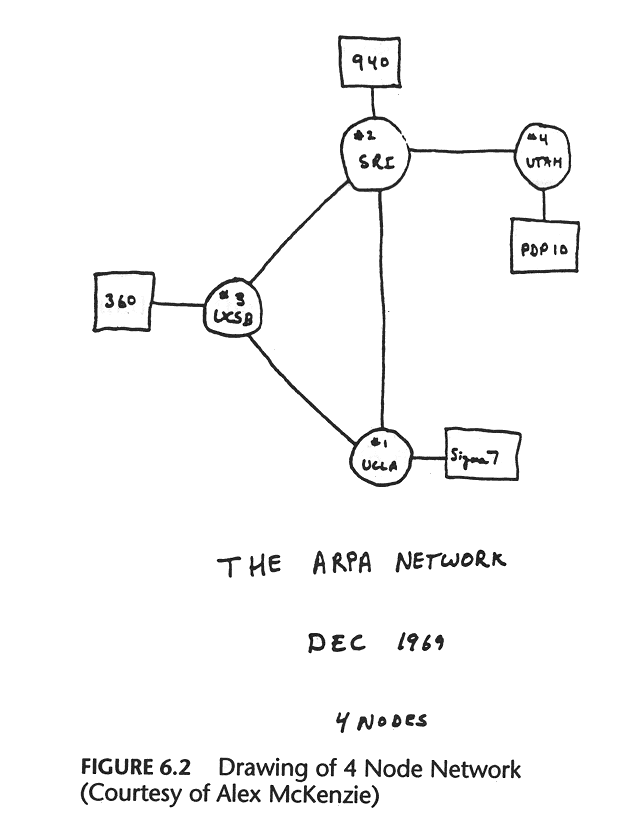
This issue was occuring now because the ARPANET was on the verge of switching from its original NCP protocol, to the TCP/IP protocol which powers what we now call the Internet. With that switch suddenly there would be a multitude of interconnected networks (an ‘Inter… net’) requiring a more ‘hierarchical’ domain system where ARPANET could resolve its own domains while the other networks resolved theirs.
Other networks at the time had great names like “COMSAT”, “CHAOSNET”, “UCLNET” and “INTELPOSTNET” and were maintained by groups of universities and companies all around the US who wanted to be able to communicate, and could afford to lease 56k lines from the phone company and buy the requisite PDP-11s to handle routing.

In the original ARPANET design, a central Network Information Center (NIC) was responsible for maintaining a file listing every host on the network. The file was known as the HOSTS.TXT file, similar to the /etc/hosts file on a Linux or OS X system today. Every network change would require the NIC to FTP (a protocol invented in 1971) to every host on the network, a significant load on their infrastructure.
Having a single file list every host on the Internet would, of course, not scale indefinitely. The priority was email, however, as it was the predominant addressing challenge of the day. Their ultimate conclusion was to create a hierarchical system in which you could query an external system for just the domain or set of domains you needed. In their words: “The conclusion in this area was that the current ‘user@host’ mailbox identifier should be extended to ‘[email protected]’ where ‘domain’ could be a hierarchy of domains.” And the domain was born.
It’s important to dispel any illusion that these decisions were made with prescience for the future the domain name would have. In fact, their elected solution was primarily decided because it was the “one causing least difficulty for existing systems.” For example, one proposal was for email addresses to be of the form <user>.<host>@<domain>. If email usernames of the day hadn’t already had ‘.’ characters you might be emailing me at ‘zack.cloudflare@com’ today.
What is Cloudflare?
Cloudflare allows you to move caching, load balancing, rate limiting, and even network firewall and code execution out of your infrastructure to our points of presence within milliseconds of virtually every Internet user.
Read A Case Study
Contact Sales
UUCP and the Bang Path
It has been said that the principal function of an operating system is to define a number of different names for the same object, so that it can busy itself keeping track of the relationship between all of the different names. Network protocols seem to have somewhat the same characteristic.
— David D. Clark, 1982
Another failed proposal involved separating domain components with the exclamation mark (!). For example, to connect to the ISIA host on ARPANET, you would connect to !ARPA!ISIA. You could then query for hosts using wildcards, so !ARPA!* would return to you every ARPANET host.
This method of addressing wasn’t a crazy divergence from the standard, it was an attempt to maintain it. The system of exclamation separated hosts dates to a data transfer tool called UUCP created in 1976. If you’re reading this on an OS X or Linux computer, uucp is likely still installed and available at the terminal.
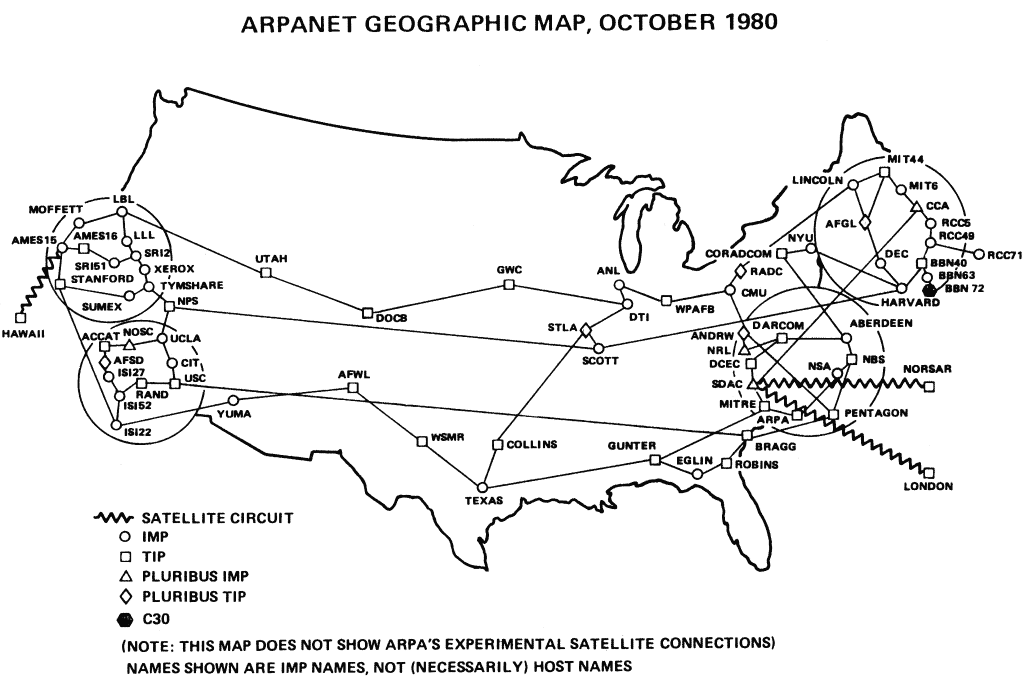
ARPANET was introduced in 1969, and quickly became a powerful communication tool… among the handful of universities and government institutions which had access to it. The Internet as we know it wouldn’t become publically available outside of research institutions until 1991, twenty one years later. But that didn’t mean computer users weren’t communicating.

In the era before the Internet, the general method of communication between computers was with a direct point-to-point dial up connection. For example, if you wanted to send me a file, you would have your modem call my modem, and we would transfer the file. To craft this into a network of sorts, UUCP was born.
In this system, each computer has a file which lists the hosts its aware of, their phone number, and a username and password on that host. You then craft a ‘path’, from your current machine to your destination, through hosts which each know how to connect to the next:
sw-hosts!digital-lobby!zack

This address would form not just a method of sending me files or connecting with my computer directly, but also would be my email address. In this era before ‘mail servers’, if my computer was off you weren’t sending me an email.
While use of ARPANET was restricted to top-tier universities, UUCP created a bootleg Internet for the rest of us. It formed the basis for both Usenet and the BBS system.
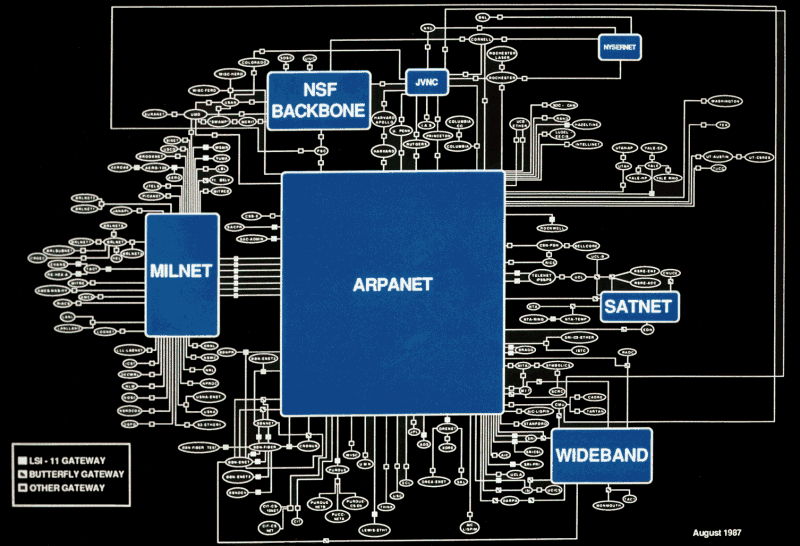
DNS
Ultimately, the DNS system we still use today would be proposed in 1983. If you run a DNS query today, for example using the dig tool, you’ll likely see a response which looks like this:
;; ANSWER SECTION:
google.com. 299 IN A 172.217.4.206
This is informing us that google.com is reachable at 172.217.4.206. As you might know, the A is informing us that this is an ‘address’ record, mapping a domain to an IPv4 address. The 299 is the ‘time to live’, letting us know how many more seconds this value will be valid for, before it should be queried again. But what does the IN mean?
IN stands for ‘Internet’. Like so much of this, the field dates back to an era when there were several competing computer networks which needed to interoperate. Other potential values were CH for the CHAOSNET or HS for Hesiod which was the name service of the Athena system. CHAOSNET is long dead, but a much evolved version of Athena is still used by students at MIT to this day. You can find the list of DNS classes on the IANA website, but it’s no surprise only one potential value is in common use today.
TLDs
It is extremely unlikely that any other TLDs will be created.
— John Postel, 1994
Once it was decided that domain names should be arranged hierarchically, it became necessary to decide what sits at the root of that hierarchy. That root is traditionally signified with a single ‘.’. In fact, ending all of your domain names with a ‘.’ is semantically correct, and will absolutely work in your web browser: google.com.
The first TLD was .arpa. It allowed users to address their old traditional ARPANET hostnames during the transition. For example, if my machine was previously registered as hfnet, my new address would be hfnet.arpa. That was only temporary, during the transition, server administrators had a very important choice to make: which of the five TLDs would they assume? “.com”, “.gov”, “.org”, “.edu” or “.mil”.
When we say DNS is hierarchical, what we mean is there is a set of root DNS servers which are responsible for, for example, turning .com into the .com nameservers, who will in turn answer how to get to google.com. The root DNS zone of the internet is composed of thirteen DNS server clusters. There are only 13 server clusters, because that’s all we can fit in a single UDP packet. Historically, DNS has operated through UDP packets, meaning the response to a request can never be more than 512 bytes.
; This file holds the information on root name servers needed to
; initialize cache of Internet domain name servers
; (e.g. reference this file in the "cache . "
; configuration file of BIND domain name servers).
;
; This file is made available by InterNIC
; under anonymous FTP as
; file /domain/named.cache
; on server FTP.INTERNIC.NET
; -OR- RS.INTERNIC.NET
;
; last update: March 23, 2016
; related version of root zone: 2016032301
;
; formerly NS.INTERNIC.NET
;
. 3600000 NS A.ROOT-SERVERS.NET.
A.ROOT-SERVERS.NET. 3600000 A 198.41.0.4
A.ROOT-SERVERS.NET. 3600000 AAAA 2001:503:ba3e::2:30
;
; FORMERLY NS1.ISI.EDU
;
. 3600000 NS B.ROOT-SERVERS.NET.
B.ROOT-SERVERS.NET. 3600000 A 192.228.79.201
B.ROOT-SERVERS.NET. 3600000 AAAA 2001:500:84::b
;
; FORMERLY C.PSI.NET
;
. 3600000 NS C.ROOT-SERVERS.NET.
C.ROOT-SERVERS.NET. 3600000 A 192.33.4.12
C.ROOT-SERVERS.NET. 3600000 AAAA 2001:500:2::c
;
; FORMERLY TERP.UMD.EDU
;
. 3600000 NS D.ROOT-SERVERS.NET.
D.ROOT-SERVERS.NET. 3600000 A 199.7.91.13
D.ROOT-SERVERS.NET. 3600000 AAAA 2001:500:2d::d
;
; FORMERLY NS.NASA.GOV
;
. 3600000 NS E.ROOT-SERVERS.NET.
E.ROOT-SERVERS.NET. 3600000 A 192.203.230.10
;
; FORMERLY NS.ISC.ORG
;
. 3600000 NS F.ROOT-SERVERS.NET.
F.ROOT-SERVERS.NET. 3600000 A 192.5.5.241
F.ROOT-SERVERS.NET. 3600000 AAAA 2001:500:2f::f
;
; FORMERLY NS.NIC.DDN.MIL
;
. 3600000 NS G.ROOT-SERVERS.NET.
G.ROOT-SERVERS.NET. 3600000 A 192.112.36.4
;
; FORMERLY AOS.ARL.ARMY.MIL
;
. 3600000 NS H.ROOT-SERVERS.NET.
H.ROOT-SERVERS.NET. 3600000 A 198.97.190.53
H.ROOT-SERVERS.NET. 3600000 AAAA 2001:500:1::53
;
; FORMERLY NIC.NORDU.NET
;
. 3600000 NS I.ROOT-SERVERS.NET.
I.ROOT-SERVERS.NET. 3600000 A 192.36.148.17
I.ROOT-SERVERS.NET. 3600000 AAAA 2001:7fe::53
;
; OPERATED BY VERISIGN, INC.
;
. 3600000 NS J.ROOT-SERVERS.NET.
J.ROOT-SERVERS.NET. 3600000 A 192.58.128.30
J.ROOT-SERVERS.NET. 3600000 AAAA 2001:503:c27::2:30
;
; OPERATED BY RIPE NCC
;
. 3600000 NS K.ROOT-SERVERS.NET.
K.ROOT-SERVERS.NET. 3600000 A 193.0.14.129
K.ROOT-SERVERS.NET. 3600000 AAAA 2001:7fd::1
;
; OPERATED BY ICANN
;
. 3600000 NS L.ROOT-SERVERS.NET.
L.ROOT-SERVERS.NET. 3600000 A 199.7.83.42
L.ROOT-SERVERS.NET. 3600000 AAAA 2001:500:9f::42
;
; OPERATED BY WIDE
;
. 3600000 NS M.ROOT-SERVERS.NET.
M.ROOT-SERVERS.NET. 3600000 A 202.12.27.33
M.ROOT-SERVERS.NET. 3600000 AAAA 2001:dc3::35
; End of file
Root DNS servers operate in safes, inside locked cages. A clock sits on the safe to ensure the camera feed hasn’t been looped. Particularily given how slow DNSSEC implementation has been, an attack on one of those servers could allow an attacker to redirect all of the Internet traffic for a portion of Internet users. This, of course, makes for the most fantastic heist movie to have never been made.
Unsurprisingly, the nameservers for top-level TLDs don’t actually change all that often. 98% of the requests root DNS servers receive are in error, most often because of broken and toy clients which don’t properly cache their results. This became such a problem that several root DNS operators had to spin up special servers just to return ‘go away’ to all the people asking for reverse DNS lookups on their local IP addresses.
The TLD nameservers are administered by different companies and governments all around the world (Verisign manages .com). When you purchase a .com domain, about $0.18 goes to the ICANN, and $7.85 goes to Verisign.
Punycode
It is rare in this world that the silly name us developers think up for a new project makes it into the final, public, product. We might name the company database Delaware (because that’s where all the companies are registered), but you can be sure by the time it hits production it will be CompanyMetadataDatastore. But rarely, when all the stars align and the boss is on vacation, one slips through the cracks.
Punycode is the system we use to encode unicode into domain names. The problem it is solving is simple, how do you write 比薩.com when the entire internet system was built around using the ASCII alphabet whose most foreign character is the tilde?
It’s not a simple matter of switching domains to use unicode. The original documents which govern domains specify they are to be encoded in ASCII. Every piece of internet hardware from the last fourty years, including the Cisco and Juniper routers used to deliver this page to you make that assumption.
The web itself was never ASCII-only. It was actually originally concieved to speak ISO 8859-1 which includes all of the ASCII characters, but adds an additional set of special characters like ¼ and letters with special marks like ä. It does not, however, contain any non-Latin characters.
This restriction on HTML was ultimately removed in 2007 and that same year Unicode became the most popular character set on the web. But domains were still confined to ASCII.
As you might guess, Punycode was not the first proposal to solve this problem. You most likely have heard of UTF-8, which is a popular way of encoding Unicode into bytes (the 8 is for the eight bits in a byte). In the year 2000 several members of the Internet Engineering Task Force came up with UTF-5. The idea was to encode Unicode into five bit chunks. You could then map each five bits into a character allowed (A-V & 0-9) in domain names. So if I had a website for Japanese language learning, my site 日本語.com would become the cryptic M5E5M72COA9E.com.
This encoding method has several disadvantages. For one, A-V and 0-9 are used in the output encoding, meaning if you wanted to actually include one of those characters in your doman, it had to be encoded like everything else. This made for some very long domains, which is a serious problem when each segment of a domain is restricted to 63 characters. A domain in the Myanmar language would be restricted to no more than 15 characters. The proposal does make the very interesting suggestion of using UTF-5 to allow Unicode to be transmitted by Morse code and telegram though.
There was also the question of how to let clients know that this domain was encoded so they could display them in the appropriate Unicode characters, rather than showing M5E5M72COA9E.com in my address bar. There were several suggestions, one of which was to use an unused bit in the DNS response. It was the “last unused bit in the header”, and the DNS folks were “very hesitant to give it up” however.
Another suggestion was to start every domain using this encoding method with ra--. At the time (mid-April 2000), there were no domains which happened to start with those particular characters. If I know anything about the Internet, someone registered an ra-- domain out of spite immediately after the proposal was published.
The ultimate conclusion, reached in 2003, was to adopt a format called Punycode which included a form of delta compression which could dramatically shorten encoded domain names. Delta compression is a particularily good idea because the odds are all of the characters in your domain are in the same general area within Unicode. For example, two characters in Farsi are going to be much closer together than a Farsi character and another in Hindi. To give an example of how this works, if we take the nonsense phrase:
يذؽ
In an uncompressed format, that would be stored as the three characters [1610, 1584, 1597] (based on their Unicode code points). To compress this we first sort it numerically (keeping track of where the original characters were): [1584, 1597, 1610]. Then we can store the lowest value (1584), and the delta between that value and the next character (13), and again for the following character (23), which is significantly less to transmit and store.
Punycode then (very) efficiently encodes those integers into characters allowed in domain names, and inserts an xn-- at the beginning to let consumers know this is an encoded domain. You’ll notice that all the Unicode characters end up together at the end of the domain. They don’t just encode their value, they also encode where they should be inserted into the ASCII portion of the domain. To provide an example, the website 熱狗sales.com becomes xn--sales-r65lm0e.com. Anytime you type a Unicode-based domain name into your browser’s address bar, it is encoded in this way.
This transformation could be transparent, but that introduces a major security problem. All sorts of Unicode characters print identically to existing ASCII characters. For example, you likely can’t see the difference between Cyrillic small letter a (“а”) and Latin small letter a (“a”). If I register Cyrillic аmazon.com (xn--mazon-3ve.com), and manage to trick you into visiting it, it’s gonna be hard to know you’re on the wrong site. For that reason, when you visit 🍕💩.ws, your browser somewhat lamely shows you xn--vi8hiv.ws in the address bar.
Protocol
The first portion of the URL is the protocol which should be used to access it. The most common protocol is http, which is the simple document transfer protocol Tim Berners-Lee invented specifically to power the web. It was not the only option. Some people believed we should just use Gopher. Rather than being general-purpose, Gopher is specifically designed to send structured data similar to how a file tree is structured.
For example, if you request the /Cars endpoint, it might return:
1Chevy Camaro /Archives/cars/cc gopher.cars.com 70
iThe Camero is a classic fake (NULL) 0
iAmerican Muscle car fake (NULL) 0
1Ferrari 451 /Factbook/ferrari/451 gopher.ferrari.net 70
which identifies two cars, along with some metadata about them and where you can connect to for more information. The understanding was your client would parse this information into a usable form which linked the entries with the destination pages.
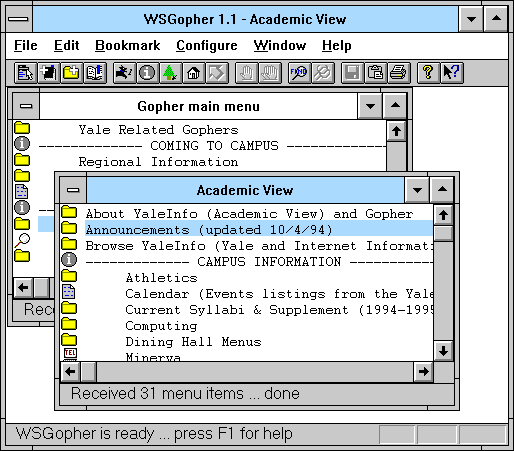
The first popular protocol was FTP, which was created in 1971, as a way of listing and downloading files on remote computers. Gopher was a logical extension of this, in that it provided a similar listing, but included facilities for also reading the metadata about entries. This meant it could be used for more liberal purposes like a news feed or a simple database. It did not have, however, the freedom and simplicity which characterizes HTTP and HTML.
HTTP is a very simple protocol, particularily when compared to alternatives like FTP or even the HTTP/3 protocol which is rising in popularity today. First off, HTTP is entirely text based, rather than being composed of bespoke binary incantations (which would have made it significantly more efficient). Tim Berners-Lee correctly intuited that using a text-based format would make it easier for generations of programmers to develop and debug HTTP-based applications.
HTTP also makes almost no assumptions about what you’re transmitting. Despite the fact that it was invented expliticly to accompany the HTML language, it allows you to specify that your content is of any type (using the MIME Content-Type, which was a new invention at the time). The protocol itself is rather simple:
A request:
GET /index.html HTTP/1.1 Host: www.example.com
Might respond:
HTTP/1.1 200 OK
Date: Mon, 23 May 2005 22:38:34 GMT
Content-Type: text/html; charset=UTF-8
Content-Encoding: UTF-8
Content-Length: 138
Last-Modified: Wed, 08 Jan 2003 23:11:55 GMT
Server: Apache/1.3.3.7 (Unix) (Red-Hat/Linux)
ETag: "3f80f-1b6-3e1cb03b"
Accept-Ranges: bytes
Connection: close
<html>
<head>
<title>An Example Page</title>
</head>
<body>
Hello World, this is a very simple HTML document.
</body>
</html>
To put this in context, you can think of the networking system the Internet uses as starting with IP, the Internet Protocol. IP is responsible for getting a small packet of data (around 1500 bytes) from one computer to another. On top of that we have TCP, which is responsible for taking larger blocks of data like entire documents and files and sending them via many IP packets reliably. On top of that, we then implement a protocol like HTTP or FTP, which specifies what format should be used to make the data we send via TCP (or UDP, etc.) understandable and meaningful.
In other words, TCP/IP sends a whole bunch of bytes to another computer, the protocol says what those bytes should be and what they mean.
You can make your own protocol if you like, assemblying the bytes in your TCP messages however you like. The only requirement is that whoever you are talking to speaks the same language. For this reason, it’s common to standardize these protocols.
There are, of course, many less important protocols to play with. For example there is a Quote of The Day protocol (port 17), and a Random Characters protocol (port 19). They may seem silly today, but they also showcase just how important that a general-purpose document transmission format like HTTP was.
Port
The timeline of Gopher and HTTP can be evidenced by their default port numbers. Gopher is 70, HTTP 80. The HTTP port was assigned (likely by Jon Postel at the IANA) at the request of Tim Berners-Lee sometime between 1990 and 1992.
This concept, of registering ‘port numbers’ predates even the Internet. In the original NCP protocol which powered the ARPANET remote addresses were identified by 40 bits. The first 32 identified the remote host, similar to how an IP address works today. The last eight were known as the AEN (it stood for “Another Eight-bit Number”), and were used by the remote machine in the way we use a port number, to separate messages destined for different processes. In other words, the address specifies which machine the message should go to, and the AEN (or port number) tells that remote machine which application should get the message.
They quickly requested that users register these ‘socket numbers’ to limit potential collisions. When port numbers were expanded to 16 bits by TCP/IP, that registration process was continued.
While protocols have a default port, it makes sense to allow ports to also be specified manually to allow for local development and the hosting of multiple services on the same machine. That same logic was the basis for prefixing websites with www.. At the time, it was unlikely anyone was getting access to the root of their domain, just for hosting an ‘experimental’ website. But if you give users the hostname of your specific machine (dx3.cern.ch), you’re in trouble when you need to replace that machine. By using a common subdomain (www.cern.ch) you can change what it points to as needed.
The Bit In-between
As you probably know, the URL syntax places a double slash (//) between the protocol and the rest of the URL:
http://cloudflare.com
That double slash was inherited from the Apollo computer system which was one of the first networked workstations. The Apollo team had a similar problem to Tim Berners-Lee: they needed a way to separate a path from the machine that path is on. Their solution was to create a special path format:
//computername/file/path/as/usual
And TBL copied that scheme. Incidentally, he now regrets that decision, wishing the domain (in this case example.com) was the first portion of the path:
http:com/example/foo/bar/baz
URLs were never intended to be what they’ve become: an arcane way for a user to identify a site on the Web. Unfortunately, we’ve never been able to standardize URNs, which would give us a more useful naming system. Arguing that the current URL system is sufficient is like praising the DOS command line, and stating that most people should simply learn to use command line syntax. The reason we have windowing systems is to make computers easier to use, and more widely used. The same thinking should lead us to a superior way of locating specific sites on the Web.
— Dale Dougherty 1996
There are several different ways to understand the ‘Internet’. One is as a system of computers connected using a computer network. That version of the Internet came into being in 1969 with the creation of the ARPANET. Mail, files and chat all moved over that network before the creation of HTTP, HTML, or the ‘web browser’.
In 1992 Tim Berners-Lee created three things, giving birth to what we consider the Internet. The HTTP protocol, HTML, and the URL. His goal was to bring ‘Hypertext’ to life. Hypertext at its simplest is the ability to create documents which link to one another. At the time it was viewed more as a science fiction panacea, to be complimented by Hypermedia, and any other word you could add ‘Hyper’ in front of.
The key requirement of Hypertext was the ability to link from one document to another. In TBL’s time though, these documents were hosted in a multitude of formats and accessed through protocols like Gopher and FTP. He needed a consistent way to refer to a file which encoded its protocol, its host on the Internet, and where it existed on that host.
At the original World-Wide Web presentation in March of 1992 TBL described it as a ‘Universal Document Identifier’ (UDI). Many different formats were considered for this identifier:
protocol: aftp host: xxx.yyy.edu path: /pub/doc/README
PR=aftp; H=xx.yy.edu; PA=/pub/doc/README;
PR:aftp/xx.yy.edu/pub/doc/README
/aftp/xx.yy.edu/pub/doc/README
This document also explains why spaces must be encoded in URLs (%20):
The use of white space characters has been avoided in UDIs: spaces > are not legal characters. This was done because of the frequent > introduction of extraneous white space when lines are wrapped by > systems such as mail, or sheer necessity of narrow column width, and > because of the inter-conversion of various forms of white space > which occurs during character code conversion and the transfer of > text between applications.
What’s most important to understand is that the URL was fundamentally just an abbreviated way of refering to the combination of scheme, domain, port, credentials and path which previously had to be understood contextually for each different communication system.
It was first officially defined in an RFC published in 1994.
scheme:[//[user:password@]host[:port]][/]path[?query][#fragment]
This system made it possible to refer to different systems from within Hypertext, but now that virtually all content is hosted over HTTP, may not be as necessary anymore. As early as 1996 browsers were already inserting the http:// and www. for users automatically (rendering any advertisement which still contains them truly ridiculous).
Path
I do not think the question is whether people can learn the meaning of the URL, I just find it it morally abhorrent to force grandma or grandpa to understand what, in the end, are UNIX file system conventions.
— Israel del Rio 1996
The slash separated path component of a URL should be familiar to any user of any computer built in the last fifty years. The hierarchal filesystem itself was introduced by the MULTICS system. Its creator, in turn, attributes it to a two hour conversation with Albert Einstein he had in 1952.
MULTICS used the greater than symbol (>) to separated file path components. For example:
>usr>bin>local>awk
That was perfectly logical, but unfortunately the Unix folks decided to use > to represent redirection, delegating path separation to the forward slash (/).
Snapchat the Supreme Court
Wrong. We are I now see clearly *disagreeing*. You and I.
…
As a person I reserve the right to use different criteria for different purposes. I want to be able to give names to generic works, AND to particular translations AND to particular versions. I want a richer world than you propose. I don’t want to be constrained by your two-level system of “documents” and “variants”.
— Tim Berners-Lee 1993
One half of the URLs referenced by US Supreme Court opinions point to pages which no longer exist. If you were reading an academic paper in 2011, written in 2001, you have better than even odds that any given URL won’t be valid.
There was a fervent belief in 1993 that the URL would die, in favor of the ‘URN’. The Uniform Resource Name is a permanent reference to a given piece of content which, unlike a URL, will never change or break. Tim Berners-Lee first described the “urgent need” for them as early as 1991.
The simplest way to craft a URN might be to simply use a cryptographic hash of the contents of the page, for example: urn:791f0de3cfffc6ec7a0aacda2b147839. This method doesn’t meet the criteria of the web community though, as it wasn’t really possible to figure out who to ask to turn that hash into a piece of real content. It also didn’t account for the format changes which often happen to files (compressed vs uncompressed for example) which nevertheless represent the same content.
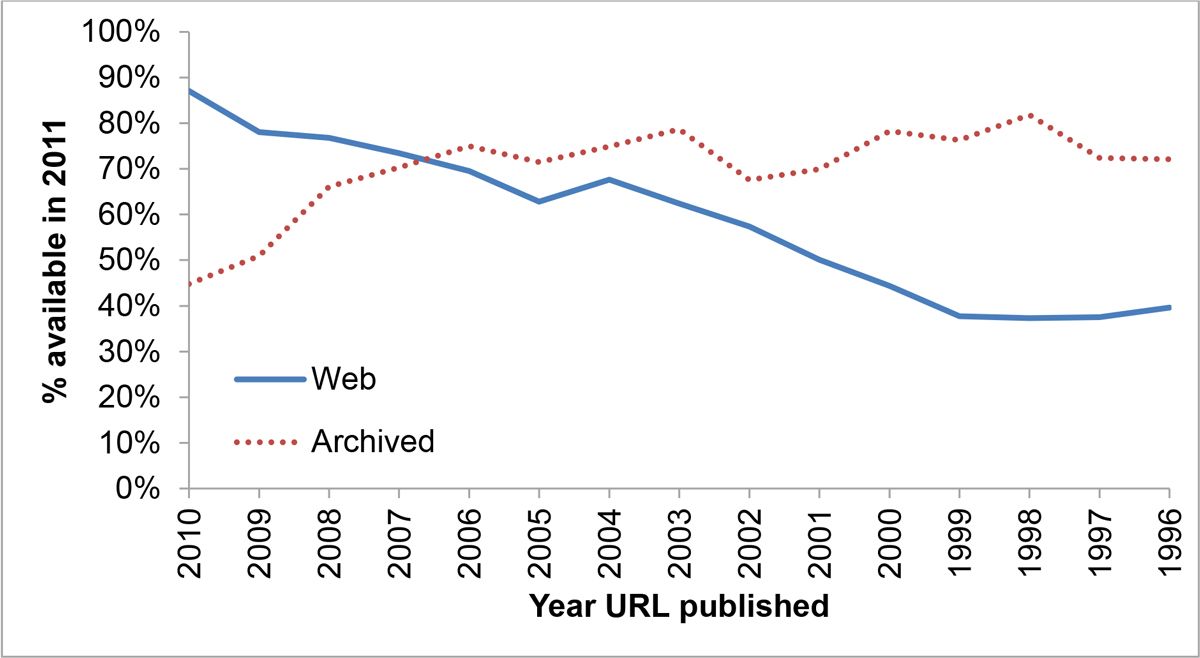
In 1996 Keith Shafer and several others proposed a solution to the problem of broken URLs. The link to this solution is now broken. Roy Fielding posted an implementation suggestion in July of 1995. That link is now broken.
I was able to find these pages through Google, which has functionally made page titles the URN of today. The URN format was ultimately finalized in 1997, and has essentially never been used since. The implementation is itself interesting. Each URN is composed of two components, an authority who can resolve a given type of URN, and the specific ID of this document in whichever format the authority understands. For example, urn:isbn:0131103628 will identify a book, forming a permanent link which can (hopefully) be turned into a set of URLs by your local isbn resolver.
Given the power of search engines, it’s possible the best URN format today would be a simple way for files to point to their former URLs. We could allow the search engines to index this information, and link us as appropriate:
<!-- On http://zack.is/history -->
<link rel="past-url" href="http://zackbloom.com/history.html">
<link rel="past-url" href="http://zack.is/history.html">
Query Params
The “application/x-www-form-urlencoded” format is in many ways an aberrant monstrosity, the result of many years of implementation accidents and compromises leading to a set of requirements necessary for interoperability, but in no way representing good design practices.
— WhatWG URL Spec
If you’ve used the web for any period of time, you are familiar with query parameters. They follow the path portion of the URL, and encode options like ?name=zack&state=mi. It may seem odd to you that queries use the ampersand character (&) which is the same character used in HTML to encode special characters. In fact, if you’ve used HTML for any period of time, you likely have had to encode ampersands in URLs, turning http://host/?x=1&y=2 into http://host/?x=1&y=2 or http://host?x=1&y=2 (that particular confusion has always existed).
You may have also noticed that cookies follow a similar, but different format: x=1;y=2 which doesn’t actually conflict with HTML character encoding at all. This idea was not lost on the W3C, who encouraged implementers to support ; as well as & in query parameters as early as 1995.
Originally, this section of the URL was strictly used for searching ‘indexes’. The Web was originally created (and its funding was based on it creating) a method of collaboration for high energy physicists. This is not to say Tim Berners-Lee didn’t know he was really creating a general-purpose communication tool. He didn’t add support for tables for years, which is probably something physicists would have needed.
In any case, these ‘physicists’ needed a way of encoding and linking to information, and a way of searching that information. To provide that, Tim Berners-Lee created the <ISINDEX> tag. If <ISINDEX> appeared on a page, it would inform the browser that this is a page which can be searched. The browser should show a search field, and allow the user to send a query to the server.
That query was formatted as keywords separated by plus characters (+):
http://cernvm/FIND/?sgml+cms
In fantastic Internet fashion, this tag was quickly abused to do all manner of things including providing an input to calculate square roots. It was quickly proposed that perhaps this was too specific, and we really needed a general purpose <input> tag.
That particular proposal actually uses plus signs to separate the components of what otherwise looks like a modern GET query:
http://somehost.somewhere/some/path?x=xxxx+y=yyyy+z=zzzz
This was far from universally acclaimed. Some believed we needed a way of saying that the content on the other side of links should be searchable:
<a HREF="wais://quake.think.com/INFO" INDEX=1>search</a>
Tim Berners-Lee thought we should have a way of defining strongly-typed queries:
<ISINDEX TYPE="iana:/www/classes/query/personalinfo">
I can be somewhat confident in saying, in retrospect, I am glad the more generic solution won out.
The real work on <INPUT> began in January of 1993 based on an older SGML type. It was (perhaps unfortunately), decided that <SELECT> inputs needed a separate, richer, structure:
<select name=FIELDNAME type=CHOICETYPE [value=VALUE] [help=HELPUDI]>
<choice>item 1
<choice>item 2
<choice>item 3
</select>
If you’re curious, reusing <li>, rather than introducing the <option> element was absolutely considered. There were, of course, alternative form proposals. One included some variable substituion evocative of what Angular might do today:
<ENTRYBLANK TYPE=int LENGTH=length DEFAULT=default VAR=lval>Prompt</ENTRYBLANK>
<QUESTION TYPE=float DEFAULT=default VAR=lval>Prompt</QUESTION>
<CHOICE DEFAULT=default VAR=lval>
<ALTERNATIVE VAL=value1>Prompt1 ...
<ALTERNATIVE VAL=valuen>Promptn
</CHOICE>
In this example the inputs are checked against the type specified in type, and the VAR values are available on the page for use in string substitution in URLs, à la:
http://cloudflare.com/apps/$appId
Additional proposals actually used @, rather than =, to separate query components:
name@value+name@(value&value)
It was Marc Andreessen who suggested our current method based on what he had already implemented in Mosaic:
name=value&name=value&name=value
Just two months later Mosaic would add support for method=POST forms, and ‘modern’ HTML forms were born.
Of course, it was also Marc Andreessen’s company Netscape who would create the cookie format (using a different separator). Their proposal was itself painfully shortsighted, led to the attempt to introduce a Set-Cookie2 header, and introduced fundamental structural issues we still deal with at Cloudflare to this day.
Fragments
The portion of the URL following the ‘#’ is known as the fragment. Fragments were a part of URLs since their initial specification, used to link to a specific location on the page being loaded. For example, if I have an anchor on my site:
<a name="bio"></a>
I can link to it:
http://zack.is/#bio
This concept was gradually extended to any element (rather than just anchors), and moved to the id attribute rather than name:
<h1 id="bio">Bio</h1>
Tim Berners-Lee decided to use this character based on its connection to addresses in the United States (despite the fact that he’s British by birth). In his words:
In a snail mail address in the US at least, it is common
to use the number sign for an apartment number or suite
number within a building. So 12 Acacia Av #12 means “The
building at 12 Acacia Av, and then within that the unit
known numbered 12”. It seemed to be a natural character
for the task. Now, http://bit.ly/2Ilg8Zx means
“Within resource http://bit.ly/38uDo1H, the
particular view of it known as bar”.
It turns out that the original Hypertext system, created by Douglas Englebart, also used the ‘#’ character for the same purpose. This may be coincidental or it could be a case of accidental “idea borrowing”.
Fragments are explicitly not included in HTTP requests, meaning they only live inside the browser. This concept proved very valuable when it came time to implement client-side navigation (before pushState was introduced). Fragments were also very valuable when it came time to think about how we can store state in URLs without actually sending it to the server. What could that mean? Let’s explore:
Molehills and Mountains
There is a whole standard, as yukky as SGML, on Electronic data Intercahnge [sic], meaning forms and form submission. I know no more except it looks like fortran backwards with no spaces.
— Tim Berners-Lee 1993
There is a popular perception that the internet standards bodies didn’t do much from the finalization of HTTP 1.1 and HTML 4.01 in 2002 to when HTML 5 really got on track. This period is also known (only by me) as the Dark Age of XHTML. The truth is though, the standardization folks were fantastically busy. They were just doing things which ultimately didn’t prove all that valuable.
One such effort was the Semantic Web. The dream was to create a Resource Description Framework (editorial note: run away from any team which seeks to create a framework), which would allow metadata about content to be universally expressed. For example, rather than creating a nice web page about my Corvette Stingray, I could make an RDF document describing its size, color, and the number of speeding tickets I had gotten while driving it.
This is, of course, in no way a bad idea. But the format was XML based, and there was a big chicken-and-egg problem between having the entire world documented, and having the browsers do anything useful with that documentation.
It did however provide a powerful environment for philosophical argument. One of the best such arguments lasted at least ten years, and was known by the masterful codename ‘httpRange-14’.
httpRange-14 sought to answer the fundamental question of what a URL is. Does a URL always refer to a document, or can it refer to anything? Can I have a URL which points to my car?
They didn’t attempt to answer that question in any satisfying manner. Instead they focused on how and when we can use 303 redirects to point users from links which aren’t documents to ones which are, and when we can use URL fragments (the bit after the ‘#’) to point users to linked data.
To the pragmatic mind of today, this might seem like a silly question. To many of us, you can use a URL for whatever you manage to use it for, and people will use your thing or they won’t. But the Semantic Web cares for nothing more than semantics, so it was on.
This particular topic was discussed on July 1st 2002, July 15th 2002, July 22nd 2002, July 29th 2002, September 16th 2002, and at least 20 other occasions through 2005. It was resolved by the great ‘httpRange-14 resolution’ of 2005, then reopened by complaints in 2007 and 2011 and a call for new solutions in 2012. The question was heavily discussed by the pedantic web group, which is very aptly named. The one thing which didn’t happen is all that much semantic data getting put on the web behind any sort of URL.
Auth
As you may know, you can include a username and password in URLs:
http://zack:[email protected]
The browser then encodes this authentication data into Base64, and sends it as a header:
Authentication: Basic emFjazpzaGhoaGho
The only reason for the Base64 encoding is to allow characters which might not be valid in a header, it provides no obscurity to the username and password values.
Particularily over the pre-SSL internet, this was very problematic. Anyone who could snoop on your connection could easily see your password. Many alternatives were proposed including Kerberos which is a widely used security protocol both then and now.
As with so many of these examples though, the simple basic auth proposal was easiest for browser manufacturers (Mosaic) to implement. This made it the first, and ultimately the only, solution until developers were given the tools to build their own authentication systems.
The Web Application
In the world of web applications, it can be a little odd to think of the basis for the web being the hyperlink. It is a method of linking one document to another, which was gradually augmented with styling, code execution, sessions, authentication, and ultimately became the social shared computing experience so many 70s researchers were trying (and failing) to create. Ultimately, the conclusion is just as true for any project or startup today as it was then: all that matters is adoption. If you can get people to use it, however slipshod it might be, they will help you craft it into what they need. The corollary is, of course, no one is using it, it doesn’t matter how technically sound it might be. There are countless tools which millions of hours of work went into which precisely no one uses today.
This was adapted from a post which originally appeared on the Eager blog. In 2016 Eager become Cloudflare Apps.
What is Cloudflare?
Cloudflare allows you to move caching, load balancing, rate limiting, and even network firewall and code execution out of your infrastructure to our points of presence within milliseconds of virtually every Internet user.
Read A Case Study
Contact Sales





 We’ve been seeing this story pop up all over the web. A group in Italy has been 3D printing valves that are saving people’s lives. In this case, the valve is a mixing device that is combining room air with pure oxygen before it is delivered to the patient. The […]
We’ve been seeing this story pop up all over the web. A group in Italy has been 3D printing valves that are saving people’s lives. In this case, the valve is a mixing device that is combining room air with pure oxygen before it is delivered to the patient. The […]







 IBM and Microsoft have signed the Vatican's "Rome Call for AI Ethics," a pledge to develop artificial intelligence in a way that protects all people and the planet, Financial Times reports. Microsoft President Brad Smith and John Kelly, IBM's executi…
IBM and Microsoft have signed the Vatican's "Rome Call for AI Ethics," a pledge to develop artificial intelligence in a way that protects all people and the planet, Financial Times reports. Microsoft President Brad Smith and John Kelly, IBM's executi…{kind=link}