




The content below is taken from the original ( Getting Compute Engine resources for batch processing just got easier), to continue reading please visit the site. Remember to respect the Author & Copyright.
If you need to run an embarrassingly parallel batch processing workload, it can be tricky to decide how many instances to create in each zone while accounting for available resources, quota limits and your reservations. We are excited to announce a new method of obtaining Compute Engine instances for batch processing that accounts for availability of resources in zones of a region. Now available in preview for regional managed instance groups, you can do this simply by specifying the ANY value in the API.
The capacity-aware deployment method is particularly useful if you need to easily create many instances with a special configuration such as virtual machines (VM) with a specific CPU platform or GPU model, preemptible VMs, or instances with a large number of cores or memory size.
Now, when deploying instances to run embarrassingly parallel batch processing, such as financial modeling or rendering, you no longer have to figure out which zones support the required hardware and how many instances to create in each zone in a region to accommodate the requested capacity.
Assuming that any distribution of instances across zones works for your batch processing job, and that the workload doesn’t require resilience against zone-level failure, you can now delegate the job of obtaining the requested capacity to a regional managed instance group. A regional MIG with the new distribution shape ANY automatically deploys instances to zones where resources are available to fulfill your request, accounting for your quota limits. This works both when you create a group or when you increase it in size.
If you use reservations to ensure that resources are available for your computation, you should specify reservation affinity in a group’s instance template. A regional MIG with distribution shape ANY utilizes the specified reservations efficiently by prioritizing consumption of unused reserved capacity before provisioning additional resources.
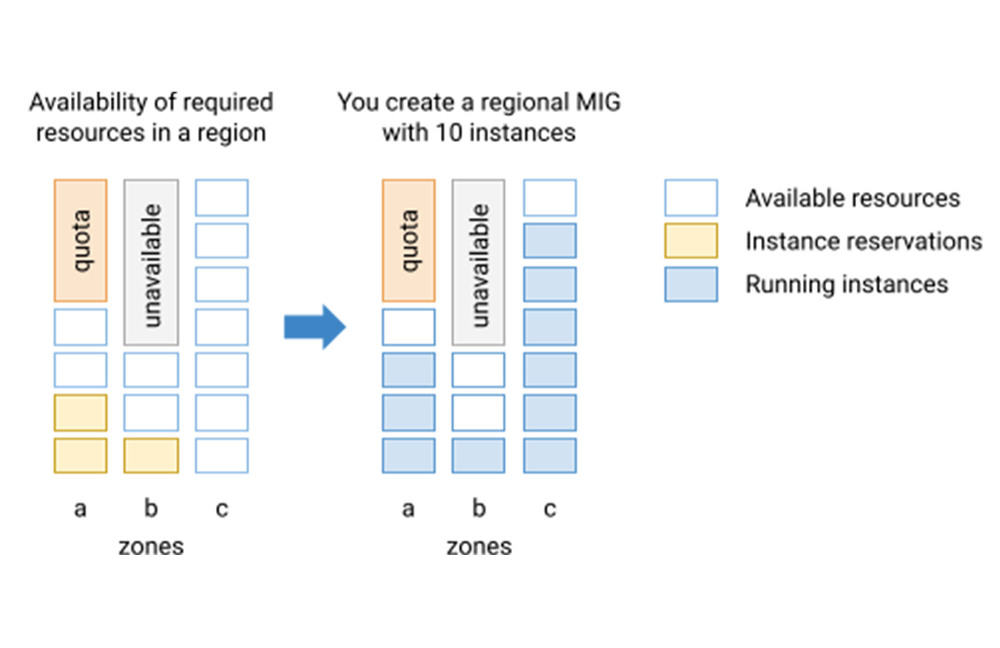
Depending on the availability of the requested resources, a regional MIG with ANY distribution might deploy all instances to a single zone or spread the instances across multiple zones. The distribution shape ANY is not suitable for highly available serving workloads such as frontend web services because a zone-level failure could result in all or most of the instances becoming unavailable if they happen to be deployed to the zone that failed.
Getting started
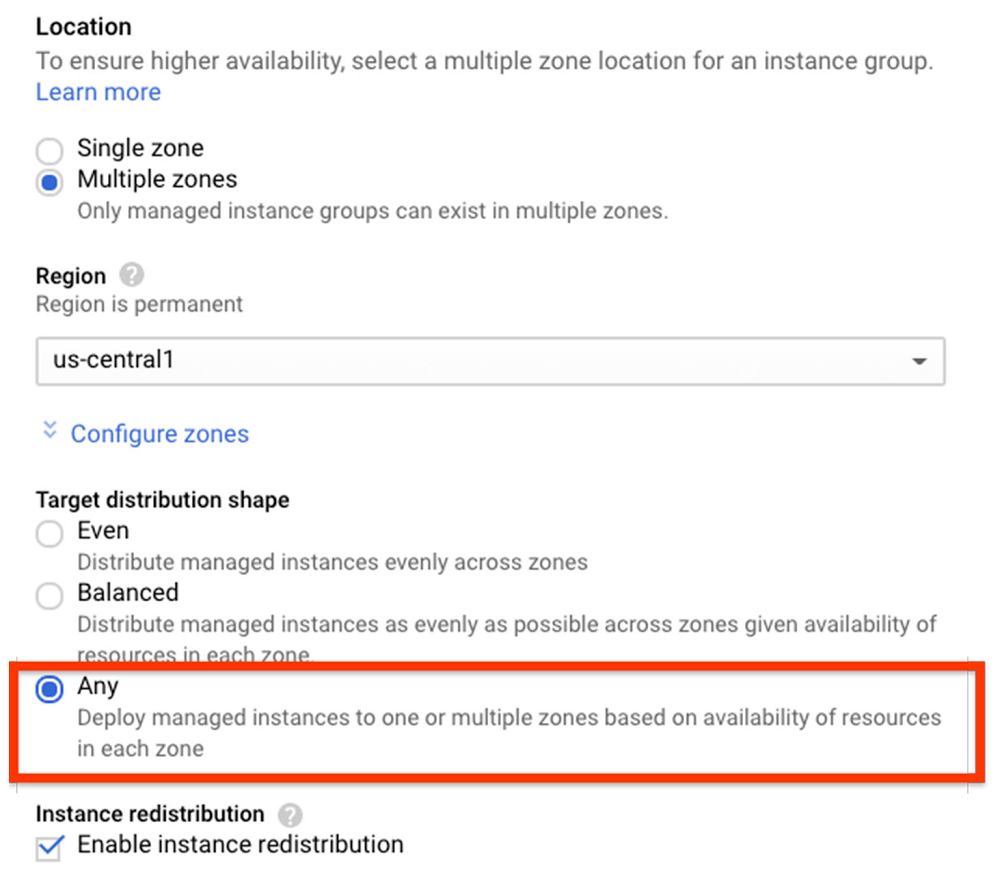
To configure the new distribution shape ANY when creating a regional MIG, look under the “Target distribution shape” setting on Create instance group screen in the Google Cloud Console:
You can also set the distribution shape to ANY for an existing regional MIG—for example, by running a gcloud command:
Summing it up
Obtaining capacity to run an embarrassingly parallel batch processing workload is easier with a regional MIG’s new distribution shape ANY. When deciding how many instances to create in each zone, the regional MIG accounts for availability of resources in each zone, accounts for your quota limits, and prioritizes consumption of specified reservations.
Visit the regional MIG documentation to learn more about creating instances using the new distribution shape ANY.
Continue your learning at the Cloud Technical Series digital event, March 23-26, and go deeper into VM migration, application modernization, GKE, data analytics, AI/ML and more. Register here.